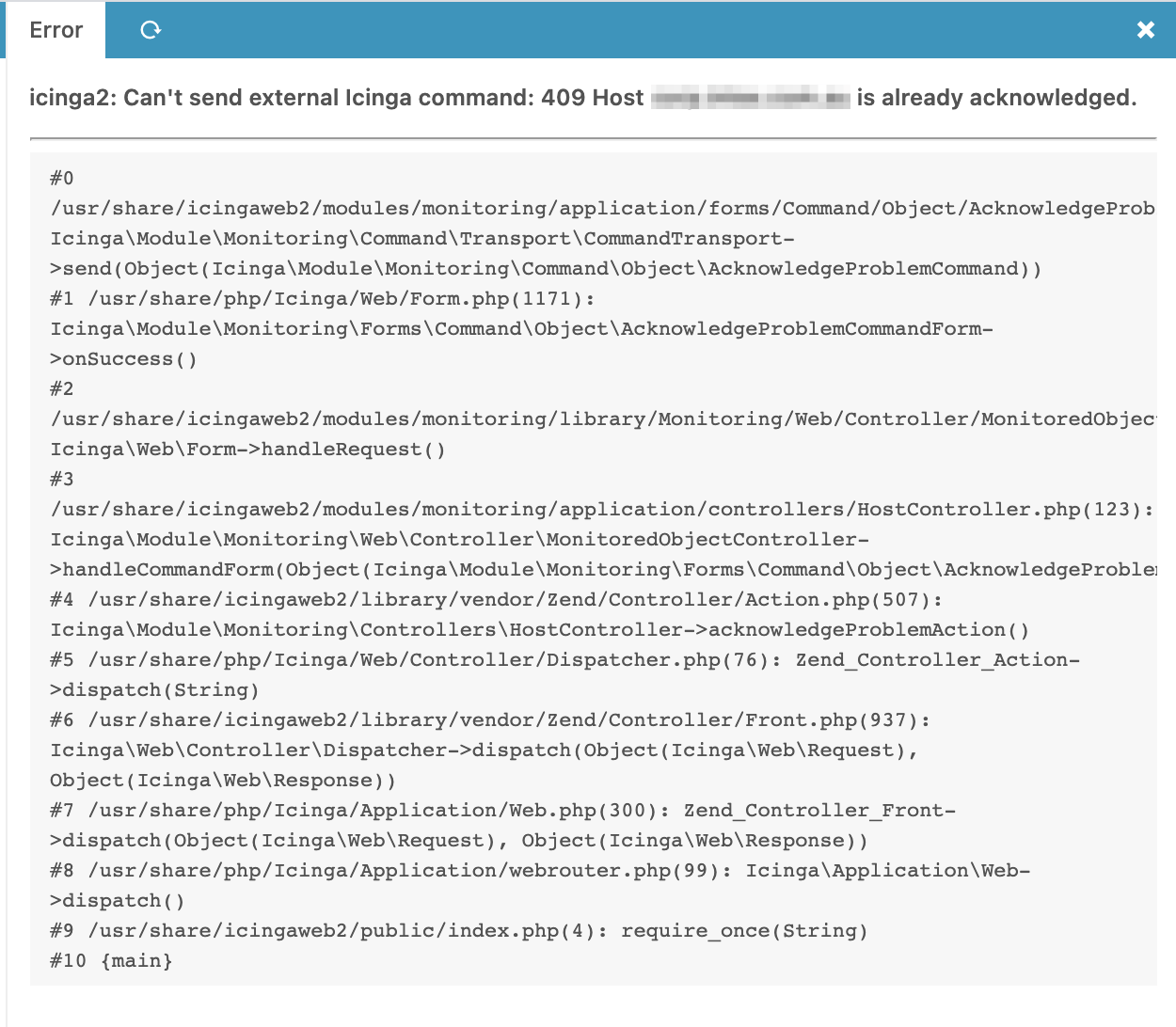
[2020-12-04 12:46:10 +1100] information/ApiListener: New client connection from [1.2.3.4]:35376 (no client certificate)
[2020-12-04 12:46:11 +1100] information/HttpServerConnection: Request: POST /v1/actions/acknowledge-problem (from [1.2.3.4]:35376), user: icingaweb2, agent: , status: Internal Server Error).
[2020-12-04 12:46:11 +1100] information/HttpServerConnection: HTTP client disconnected (from [1.2.3.4]:35376)
This appears to be affecting all of my acknowledgements for hosts and services.
If I stop the icinga2 service on my secondary master and the primary/config master takes over, the acknowledgments return, however some of the messages are missing:
I’ve tried clearing out the configs on the secondary master and have it pull a fresh config from the primary, but I can’t seem to get these acknowledgements syncing.
They connect to a local MySQL/Galera cluster node, and the database seems in-tact otherwise.
we are facing sometimes similar issues. But I still don’t know why and how to reproduce it for an issue on Git. What we saw, it happens sometimes after longer maintenance from our icinga clusters. E.g. a lot of updates on one node so this one is longer down as planed or similar situations.
Every our master has their own database and icingaweb installation.
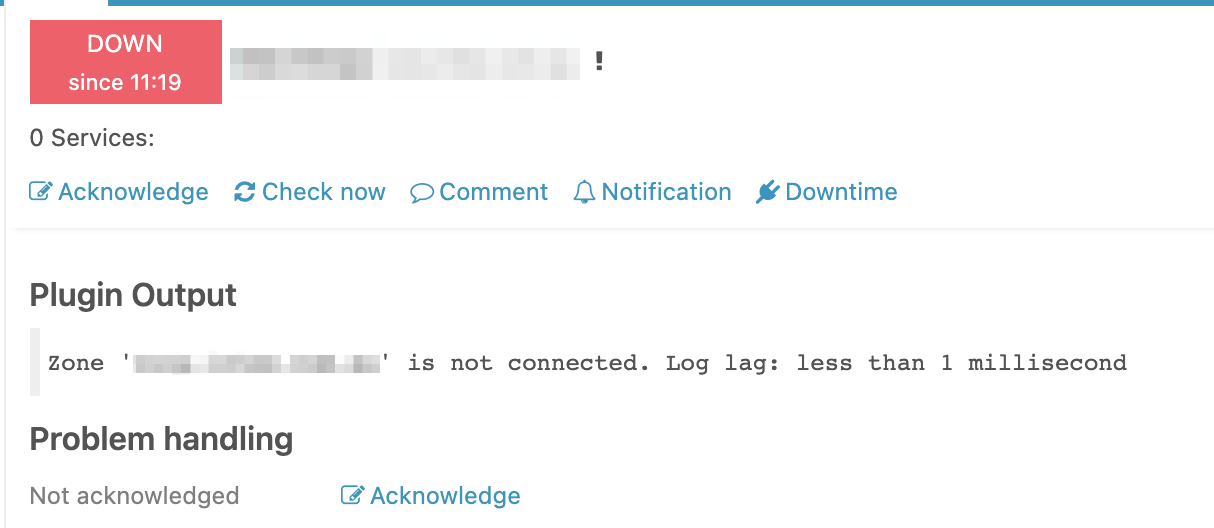
At the moment it is affecting every acknowledgement created since our upgrade from 2.10 to 2.12.2.
If I stop the secondary master, the primary takes over the IDO and everything returns to normal - as soon as I start the secondary master, the hosts/services appear as un-ack’d in Icinga Web, but give me the 409 error when I try to ack them.
Unfortunately this did not appear to fix the problem - I stopped both masters, removed the state files, and started master1, then master2, but still having checks that are acknowledged displaying as unacknowledged.
As soon as the active endpoint swaps back to my config master (master1), everything is fine again.
It appears it isn’t affecting all acknowledgements though - sometimes they go through fine.
I was able to ack some host checks where the acknowledgement was removed after deleting the state files.
Hmm, okay now I am starting to think this is a MySQL replication issue - I will try point these two servers at the same MySQL node and see if we have the same issue.
As mentioned, I was able to ack some checks, and although they didn’t appear straight away as acknowledged, they eventually went into the handled state.
This might be irrelevant - in the monitoring module of Icinga Web, should I have both of my masters configured as command transports? Or should the config master be the only one?
I was a little confused about whether both should be in there - I remember there were some bugs prior to 2.11/2.12.
Just tried that for you
Yes, put them both in the config.
Because if the only one configured isn’t available you won’t be able to issue ‘check now’, ‘acks’ or any other ad hoc commands from the web interface.
The docs state that they will be tried one after the other.
Interesting.
Though this does not really make sense to me, as only the first working command transport will/should be used, at least that’s how I understand the documentation:
Icinga Web 2 will try one transport after another to send a command until the command is successfully sent.
But I just tried it myself after having added the second master as a command transport as well.
And it really works.
I would really like to know why or where my mistake in understanding lies.
That was my understanding too - I was under the impression there were cluster/config sync bugs in ~2.10 which implied the config master should be the one to receive the transport commands, but I could be wrong on that.
Perhaps though the transport is unrelated, as I am having other issues with my core now since upgrading with timing, and I am starting to think this is the root of it all.
Do I understand you correctly: You configured API and the local command pipe (cmd-file) also? And after it works?
My knowledge was that we should better use the API (only?) instead.
Our Icinga Web is containerized, so only using the API and no local command pipe - I can rule this out being a bug or any weird behaviour, I think it was purely due to the lack of a secondary master being configured in the monitoring module…
This is what was happening prior to me adding both masters as transports - assuming the following:
Only config master (primary) configured in the monitoring module
Secondary master current active endpoint
Ack any alert
Icinga Web sends alert to primary (as it is the only configured endpoint)
Secondary master does not receive the ack as the primary is not writing to the IDO because the secondary is the active endpoint, but Icinga Web displays it as un-ack’d still.
When attempting to re-ack, Icinga Web repeats step 3.
Adding the secondary master as a transport seems that the ack was written to the IDO, hence why Icinga Web was displaying it properly.
I haven’t tried stopping one master after sending an ack since we’re running into the other issues I mentioned, so we’ve removed the secondary master entirely until I can work out whether this is a config issue or a bug in 2.12.2…
However I am also curious to know what happens if Icinga Web sends the API request to the config master/primary while it is not the active endpoint - or maybe it sends to both and assumes one will deal with it correctly.
@theFeu
May I ask you if you or anyone else from the icinga team has an explanation for this “issue” of having only one or both master servers in the command transports?
The current behavior noticed is somewhat contradicting the documentation.
maybe we get the correct way to configure this and also a way to test this better in our setups. Maybe we get also a way to identify it if this is a bug or a normal behavior. If this is a bug we can deliever logs etc.
I guess the monitored object was acked in Icinga 2, but this fact got lost from (or was missing at all in) the IDO DB. I guess because the IDO writing master’s API didn’t accept_config nor accept_commands from the one which acked the checkable.
Thanks for the reply @Al2Klimov (and thanks for asking around @theFeu).
My config master has only accept_commands = true, the second master has both set to true.
Afair setting accept_config to true on the config master is not recommended (or doesn’t even work?!).
Ack was done while the config master was the active endpoint.
As having both masters in the command transports seems to be the way to go, I will try to remember that in future setups.