I have a HA (2 master) node icinga2 setup with icingaweb2 installed on both masters.
I have put the web interface behind a Load balancer (haproxy). but when logging in, it causes a redirect loop and errors out “too many redirects”
Is the web interface incompatible with Load balancing? is there a configuration needed in the load balancer (some http header?)
Icingaweb2 is running in Apache on each of the hosts
Haproxy
backend nms_web_back
description nms/icinga2 web interface
mode http
option httpchk OPTIONS * HTTP/1.1
http-check send hdr Host nms.internal
http-check expect ! rstatus ^5 # only 5xx is bad
balance roundrobin
server nms01 host1.internal:443 check ssl verify required ca-file ca-certificates.crt fall 2 rise 2 inter 2000
server nms02 host2.internal:443 check ssl verify required ca-file ca-certificates.crt fall 2 rise 2 inter 2000
Give as much information as you can, e.g.
Icinga Web 2 version 2.8.2
Used modules and their versions (System - About)
setup 2.8.2
grafana 1.4.2
monitoring 2.8.2
Web browser used
Chrome 91
Icinga 2 version used (icinga2 --version) r2.12.4-1
So the first request to login goes to host1, and then subsequent request for load the dashboard goes to host2 which i guess fails the authentication and redirects to login again (back on host1), repeat ad infinitum
It appears based on all my debugging and googling that icingaweb2 uses cookie based session storage to maintain authentication state (logged in). Based on that it seems that it is incompatible with Load balancing without having some kind of LB persistence enabled.
Can someone confirm that this is the case? that you need to enable Load balancer stickiness/persistence so that icingaweb2 can be load balanced?
I do not know what you mean by “Which master web interface did you use”. The config I used for haproxy to LB the 2 masters is available in the reply to the thread marked “solution”, but I will repeat it here:
backend somename
mode http
cookie Icingaweb2 prefix nocache
balance roundrobin
server name1 hostname check cookie name1 fall 2 rise 2 inter 2000
server name2 hostname check cookie name2 fall 2 rise 2 inter 2000
I did load balance setup with my proxy ip 192.168.1.3 …when i run this ip address it shows alternate time the content of index.html from both master(basically the default apache webpage with slight difference in both) but i need to get the icinga web interface content when i run 192.168.1.3…
It sounds like you have a problem with your apache configuration not the haproxy Load balancer.
verify your apache configuration by visiting each server directly and ensuring that the icinga interface loads.
this might have some tips: https://icinga.com/docs/icinga-web/latest/doc/20-Advanced-Topics/
I haven’t done any work with apache configuration as all the machines are new as i am testing currently. So how do we point to get the icinga web interface instead of regular apache webpage? Do we need to do make any changes for that?
i strongly recommend you following icinga2 web installation guide: https://icinga.com/docs/icinga-web/latest/doc/02-Installation/
and make sure you have a working icinga2 install before you start trying to deal with haproxy and multinode load balancing of the icinga2 web gui
@jason.agility
Did you add both these or just the below one? as when i run haproxy/icingaweb2 on chrome it’s changing with so many redirects but doesn’t load…
backend nms_web_back
description nms/icinga2 web interface
mode http
option httpchk OPTIONS * HTTP/1.1
http-check send hdr Host nms.internal
http-check expect ! rstatus ^5 # only 5xx is bad
balance roundrobin
server nms01 host1.internal:443 check ssl verify required ca-file ca-certificates.crt fall 2 rise 2 inter 2000
server nms02 host2.internal:443 check ssl verify required ca-file ca-certificates.crt fall 2 rise 2 inter 2000
backend somename
mode http
cookie Icingaweb2 prefix nocache
balance roundrobin
server name1 hostname check cookie name1 fall 2 rise 2 inter 2000
server name2 hostname check cookie name2 fall 2 rise 2 inter 2000
I am now able to login to web interface with haproxy ip…How can i confirm if the HA has achieved with icinga? I shutdown master 1 and still see master 2 running…Any test to prove?
you should only have 1 backend for nms web interface not 2.
you suggestion on how to test HA seems like a reasonable one.
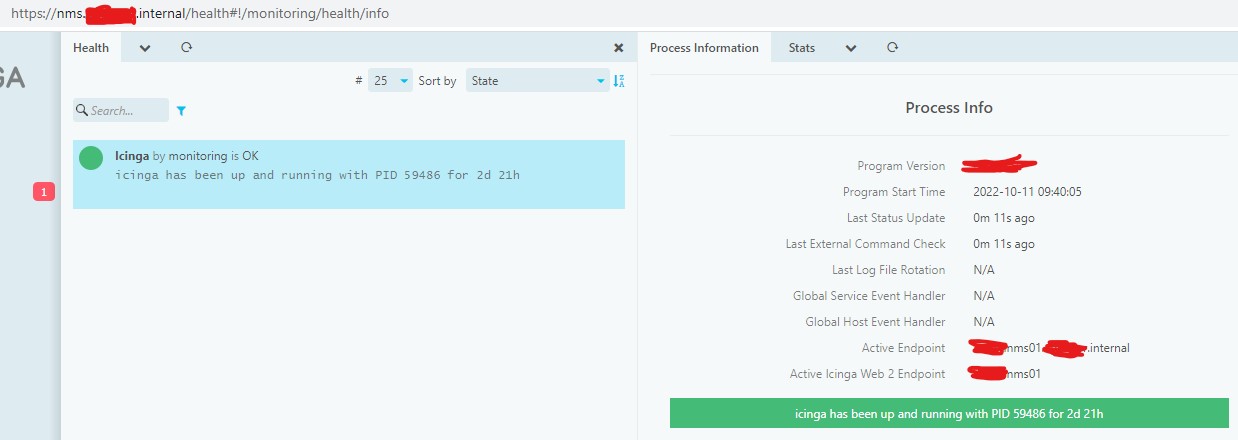
you can also check the page at “/health#!/monitoring/health/info” for the following info: “Active Icinga Web 2 Endpoint”, which will tell you which of the two icinga web hosts is currently serving the web interface. then if you take one out of load balancing, and refresh the page the value should change.
@jason.agility Thanks once again…Yeah i tried shutting down between servers and i could see changes in endpoints…This is the setup for local database on each master …How does this work if i want to use a dedicated database server instead of 2 local database? what i know is update the ido-mysql.conf with host as ip of database server and enable ha to true…is this all i have to do or any more steps ?
Another thing i noticed is when the endpoint is pointed to secondary master when primary master goes down…How can i bring the endpoint back to primary master as this would be the config master so it needs to active as soon as possible
How can i bring the endpoint back to primary master as this would be the config master so it needs to active as soon as possible
the active icinga web2 endpoint is not the same thing as the “active endpoint”, if you have you HA correctly configured the “active endpoint” should always go back to the master, but the “active icinga web2 endpoint”, may stay on the secondary (you have it round robin load balancer so you would get any of the two service the web interface)
also i couldn’t get any info about setting up dedicated database server except for adding the ip in ido-mysql.conf…Could you also please help with this
See the following post about how the primary node is chosen.
also i couldn’t get any info about setting up dedicated database server except for adding the ip in ido->mysql.conf…Could you also please help with this