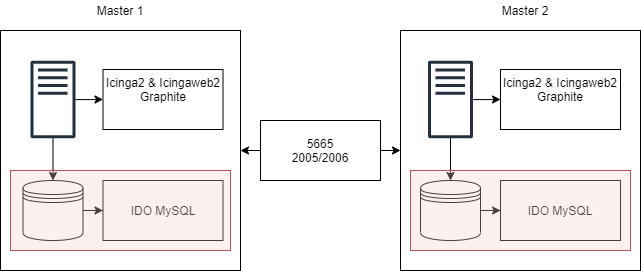
I would like to know what the best configuration for the following setup is. I read your documentation regarding distributed monitoring and could not find a setup with two database in which each master writes his own data.
Why?
we would like to deploy those two masters in separate cloud enviroments. Therefore each master should write its data to a local database located in the corresponding cloud. But in case of a failover the remaining master should still be able to work on its own, with all the hosts and services which are setup over the full cluster.
Master 1 should be the configuration master and be able to also deploy hosts and services to be monitored from Master 2 (basically all interaction should be done through master 1). In case of a failover Master 2 should take over, he will be accessable all the time through a secondary DNS entry. In case of a longer outage of Master 1 the DNS entry will be switched pointing to Master 2 from there on.
Is such a scenario supported at all?
Has someone potentially configured a similar setup and could help me getting my head around this problem?
The default setup that is supported is documented here:
You have read it already I assume.
So with the setup that you want to acquire you are going to do some manual setup.
You are going to need a VIP that will route traffic to the host that is UP.
After that the config needs to remain in sync, for this you could use ansible or any other tool.
Then You need to do the same for the DB`s, with a VIP and keep them in sync
The question is do you want a warm or cold fail over ? I will be way easier if you do a cold one. the downtime should not be more than a few seconds.
All in all not a easy setup to keep up and running, but it should be doable
@Al2Klimov
we currently try a diffenrent kind of setup closer to what is documented in “distributed monitoried” chapter.
I will update as soon as we have something working.
joining in on this one… I’ve been running HA mode, each master has a local db… however it is Galera.
every now and then something gets out of sync. Unsure if it is the database or the api/cache. When this happens it causes mass chaos. Usually takes a cleansing phase of /var/lib/icinga/icinga.state and/or the api (dirs under) to be nuked and a restart.
Would like a more simplified configuration without needing haproxy, galera, keepalive…etc
starting back on this topic. building a RHEL8 server to start with, then will clone or build a 2nd master at my DR location and go from there. Hoping this thread might pick up some momentum from others out there
We have 2 main data centers. Our DR plan is documented, but not implemented yet, but will look something like this (and require a manual failover):
Create new master/agents in 2nd DC
Disable active checking, notifications, etc @ 2nd DC
Replicate MySQL to 2nd DC (director, icinga2, icingaweb2)
Cutover DNS and turn on checking, notifications, etc… as needed.
I personally do not like this plan, but it was documented before my time. I think that I would try the above setup when given the time (other projects “outweigh” DR, go figure). Using the Icinga2 Vagrant and/or Docker stuff, you might be able to test the setup yourself pretty quickly.