Dear Community,
I’m taking care of a Icinga2 HA Cluster that is basically running well and reliably, but with every config change and following reload of the config master I get the following message for a few minutes: Remote Icinga instance 'client' is not connected to 'master'.
Until everything is up and running again (which can take 5-10 minutes) it stops running checks for some (many) services. In Icingaweb they all end up in Overdue: Late Check Results.
With several reloads a day this can be quite annoying, especially with checks that have only 1 max_check_attempts and then send false positive emails.
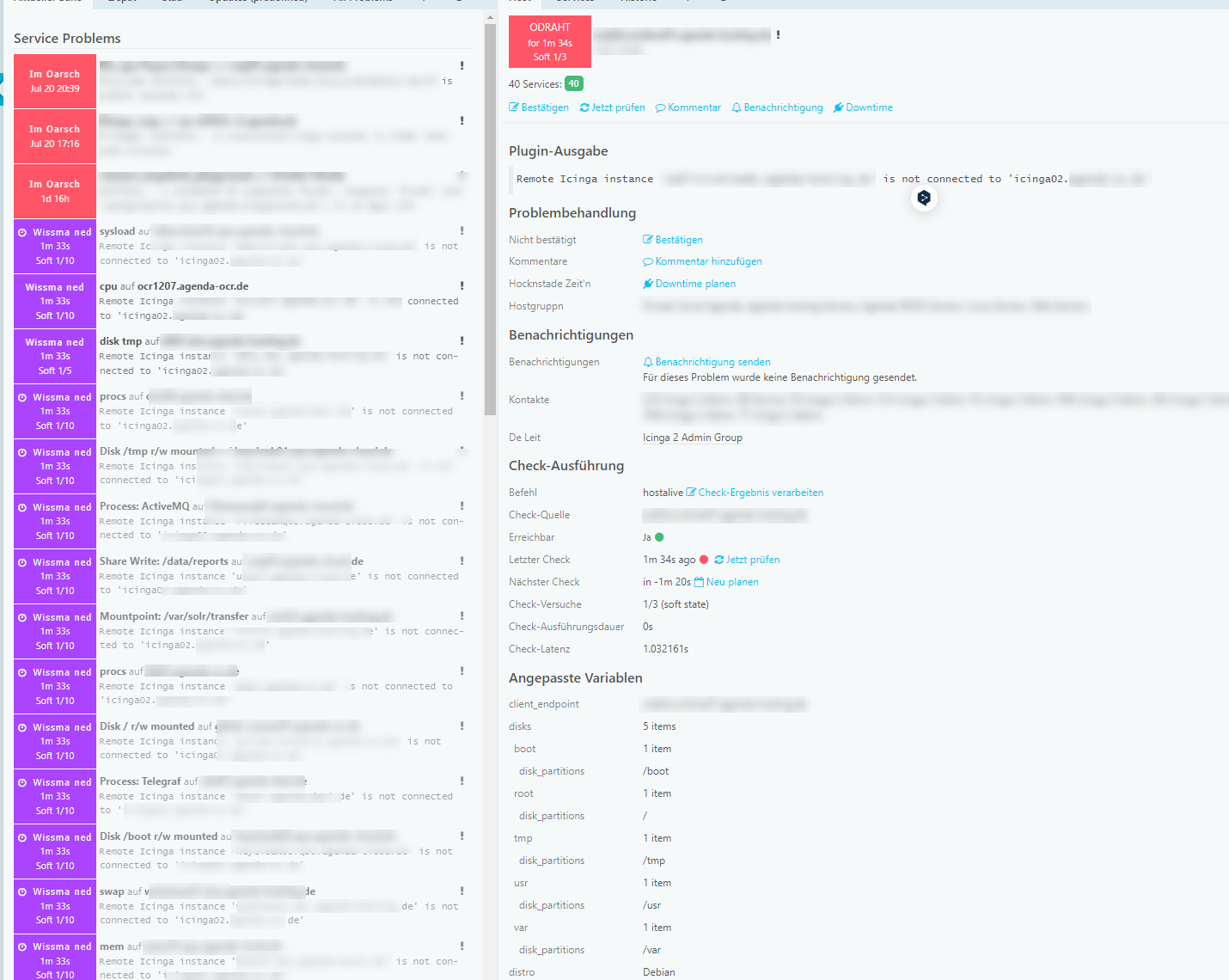
My setup: Icinga 2.13.2 on Debian 11. 2 masters (Virtual machines each: 8 cores, 8GB RAM, SSD) and 3 Sub zones with each one or two satellites.
I use file-based config with:
- 1.700 Hosts
- 27.000 Services
- 57.000 Notifications
- 24.000 Dependencies
- 312 Zones and Endpoints (each endpoint is a new zone)
reload time:
time systemctl reload icinga2.service
real 0m30.558s
user 0m0.009s
sys 0m0.001s
I measured the times with:
00:00: reload started
00:31: reload done
00:50: first services with not connected…
01:40: a lot of services with not connected
02:25: a lot of services/hosts are overdue
09:05: Everything back healthy
My questions:
What’s the reason for the described problem?
Am I the only one with such a problem in larger HA clusters?
Do I just need more power on the master servers?
Thanks in advance for your help ![]()
PS: If you also want to have such a nice language pack like me. Netways has some great ones: GitHub - NETWAYS/icingaweb2-theme-oesterreichisch: Austria Theme for Icinga Web 2