I’ve been testing Icinga2 in different cases and it’s time to share with first results.
Initial goal was to test main potential architectural bottlenecks - Icinga Masters & MySQL cluster
For testing i decided to generate load with native Icinga2 virtual Host objects on Agent Endpoints
Each virtual Host object contains:
- 50 dummy service checks with 1min frequency
- 1 random service check with 5min frequency
- 1 dummy host check with 5min frequency
Each Agent Endpoint have 1000 Host objects configured on it.
Icinga2 version in all tests: 2.11.2-1
All checks executed from Agent Endpoints and sends data to Satellite hosts, in this case its hard to see real workload from Satellite standpoint because each Agent endpoint emulates 1000 hosts, but sends all data through single TCP connection, for us it’s not critical because Satellite Zones are easy at horizontal scale.
First test in my cloud environment, followed Distributed setup strategy from Icinga2 documentation:
1 MySQL Database instance: CPU: x8(CPU MHz: 2394) RAM: 16GB
2 Masters in HA, CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Satellites in HA (3 Satellite Zones), CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Icinga2 Agents, 2 agents per each Satellite Zone, CPU: x4(CPU MHz: 2394) RAM: 4GB
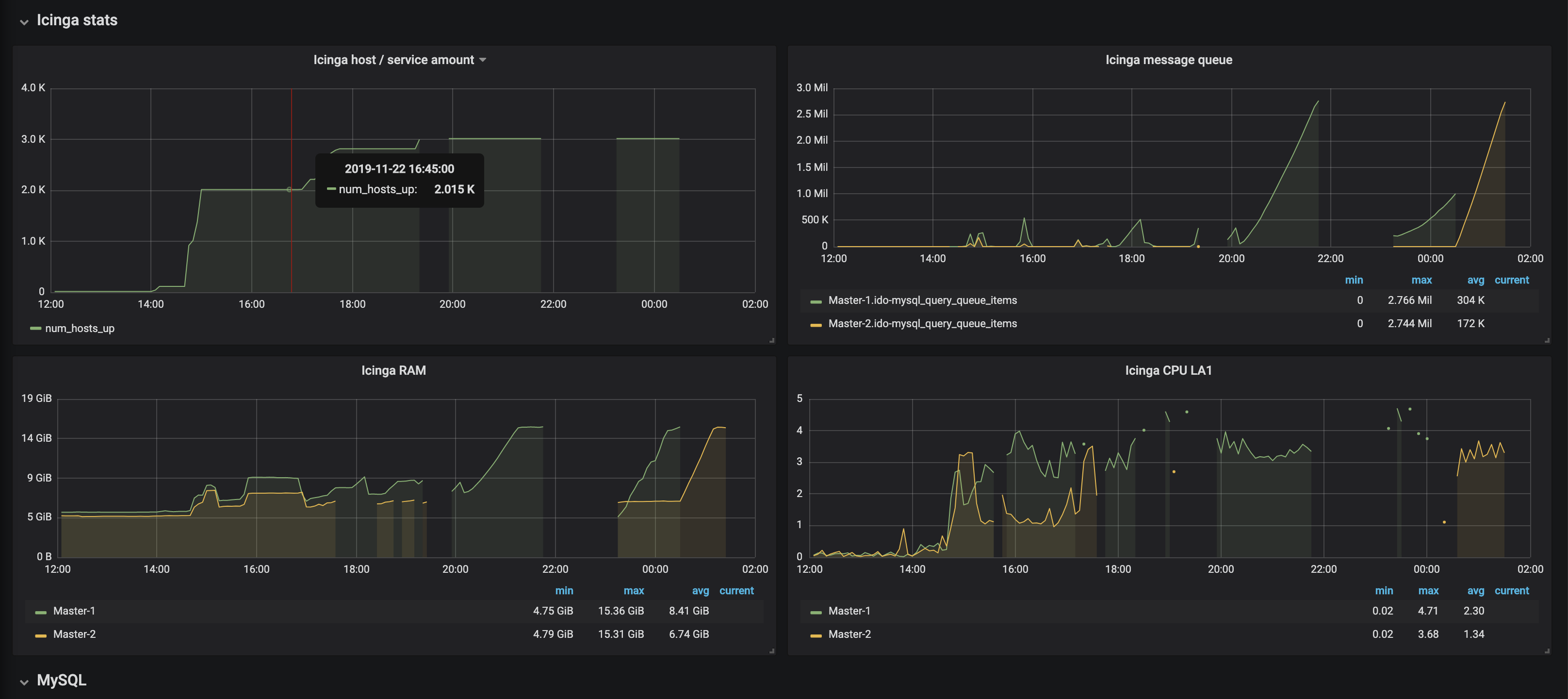
With this configuration i was able to get only 2500 Hosts working, ~2000 events per second.
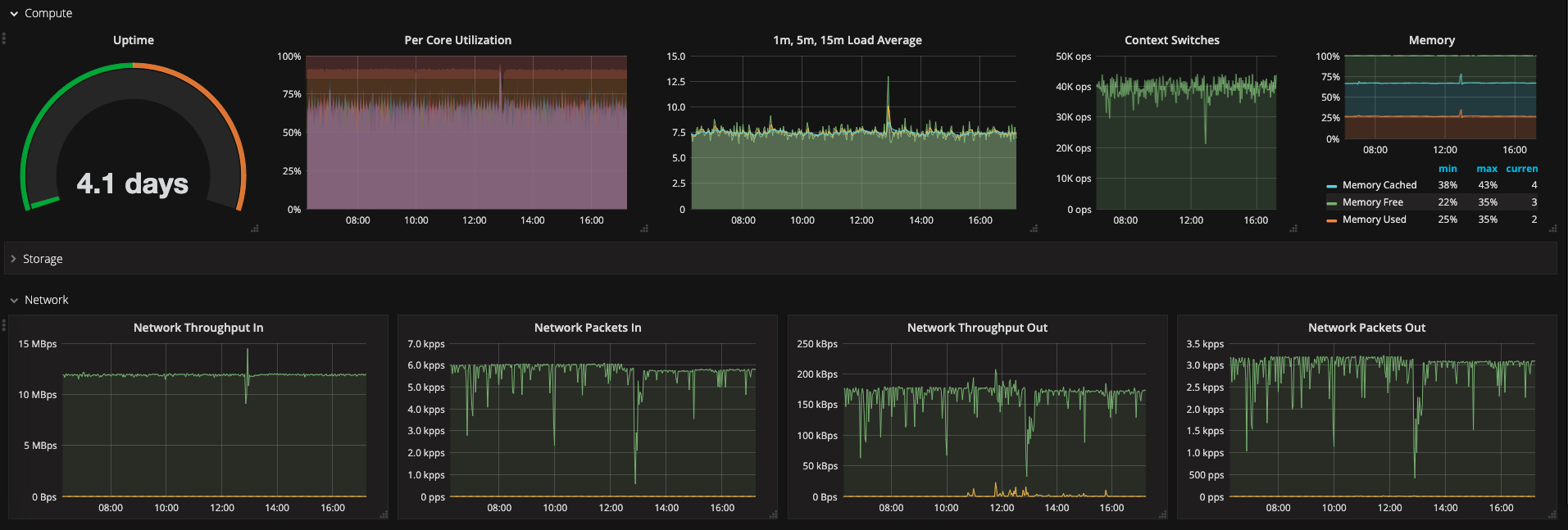
Workload on Masters was: Load Avarage: 4, RAM used: 4GB
Database also showed 1LA on system, 0% iowait and enough RAM.
When i tried to increase amount of Hosts to 3000-4000, on Masters i saw growing IDO message queues, it reached system memory limits, then process got killed by OOM killer. I’m not a strong DBA so i decided to make DB tuning at the first time, and improve our cluster config with more power of baremetal MySQL instance.
Second test with baremetal MySQL, followed Distributed setup strategy from Icinga2 documentation:
1 MySQL Database instance: CPU: 24 cores, Intel® Xeon® CPU E5-2630L v2 @ 2.40GHz, RAM: 64GB, RAID controller: Symbios Logic MegaRAID SAS 2208
2 Masters in HA, CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Satellites in HA (3 Satellite Zones), CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Icinga2 Agents, 2 agents per each Satellite Zone, CPU: x4(CPU MHz: 2394) RAM: 4GB
Showed the same results, not more than 2500 Hosts, ~2000 events per second. It was confusing so i started to look at Icinga2 performance tuning, options like MaxConcurrentChecks, or uncommenting options in systemd config like TasksMax=infinity,LimitNPROC=62883 didn’t make any effect.
Third test i made distributed configuration in other way, but with same hardware spec:
I started active search on how i can reconfigure/optimize cluster and found few interesting topics in official documentation: https://icinga.com/docs/icinga2/latest/doc/09-object-types/#idomysqlconnection
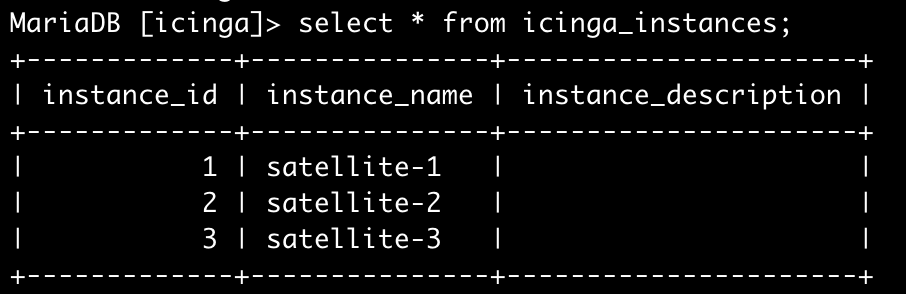
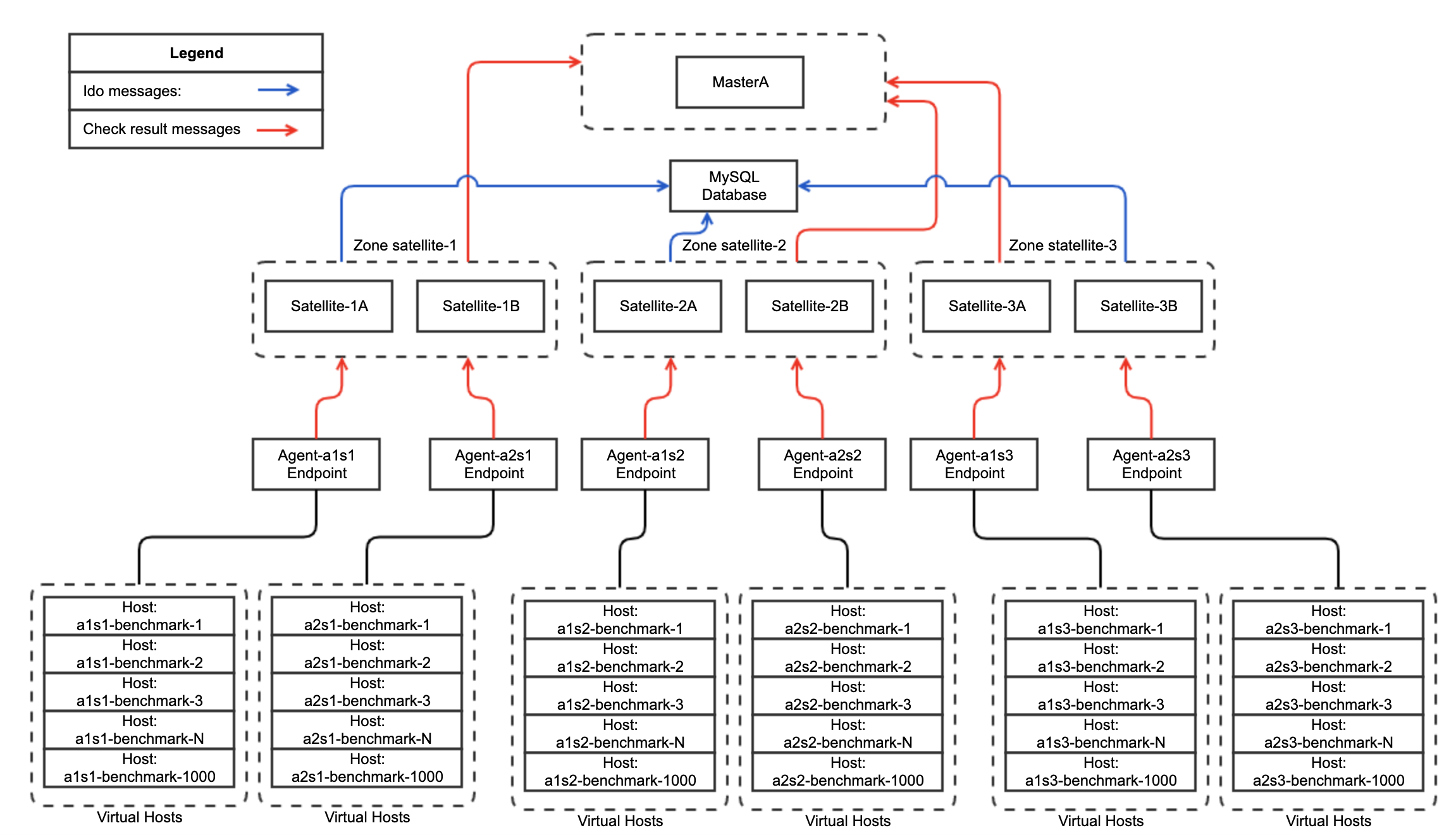
IDO feature allow to put instance_name option in config, it allow multiple icinga2 clusters to write in a single DB, i’ve got an idea to configure IDO on satellite side.
Instance name should be the same for both satellite endpoints in same HA zone and uniq per satellite zone.
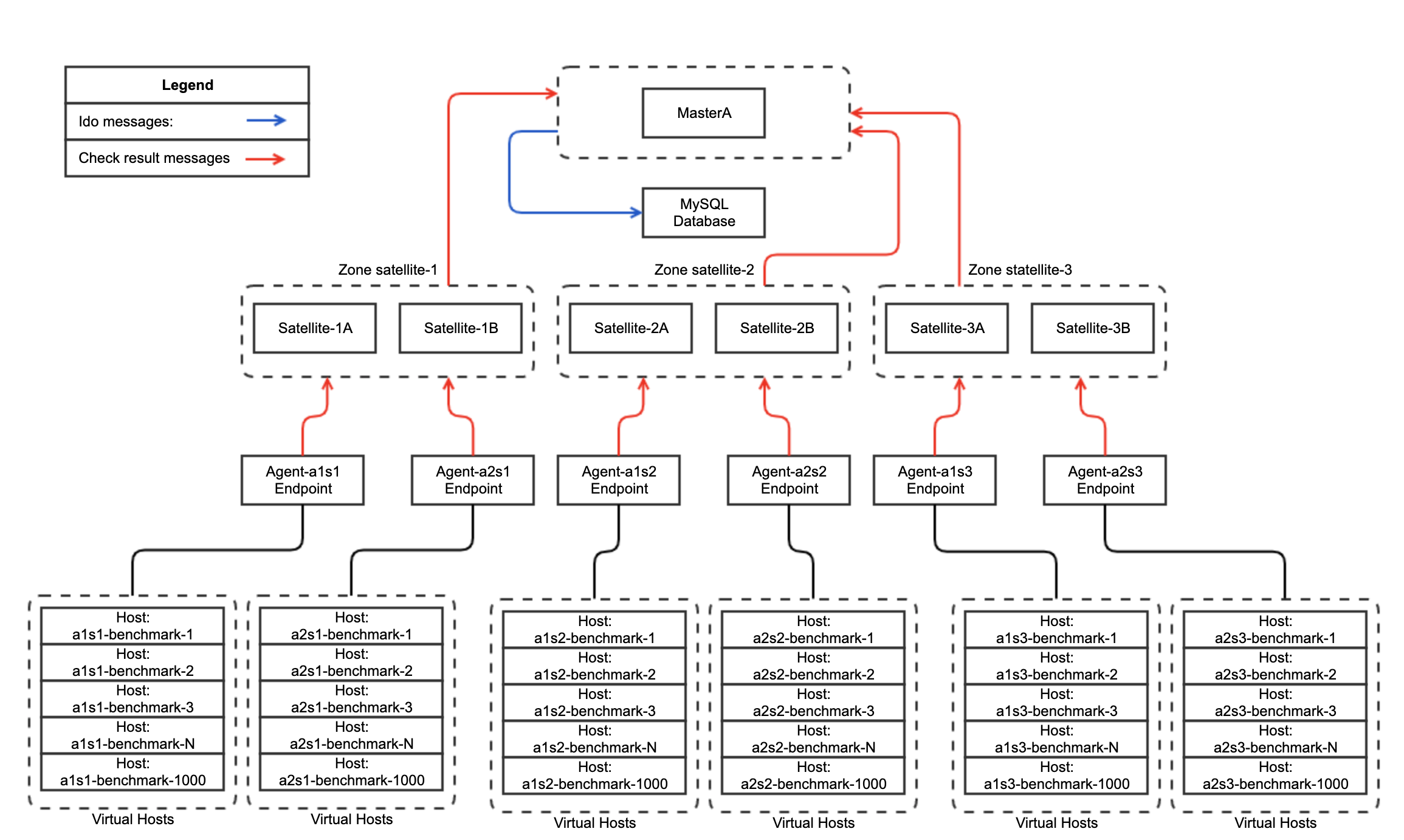
Data flow schema, red lines - check result messages send through Icinga2 Data Exchange on port 5665,
blue lines - processed check result messages sent through IDO DB
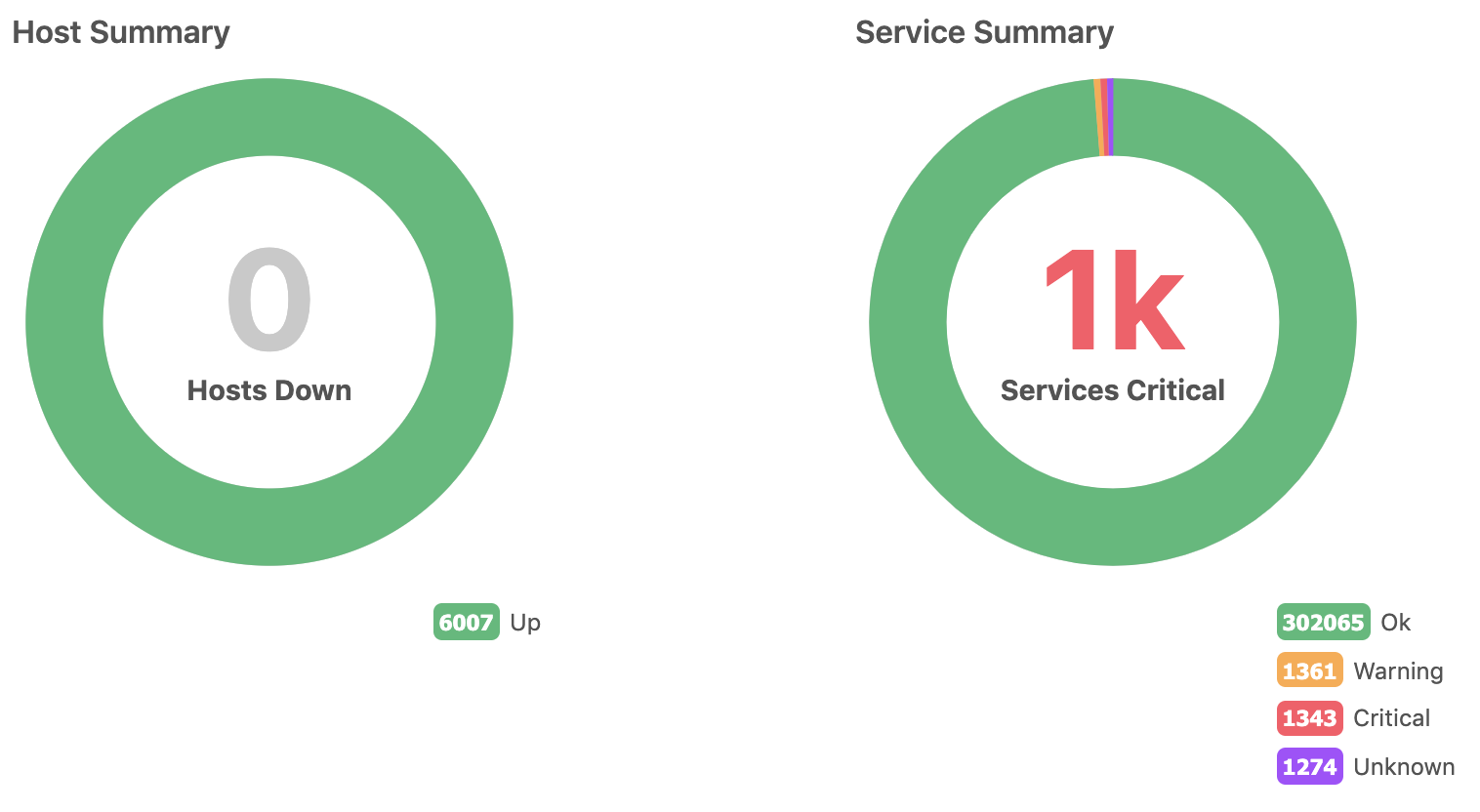
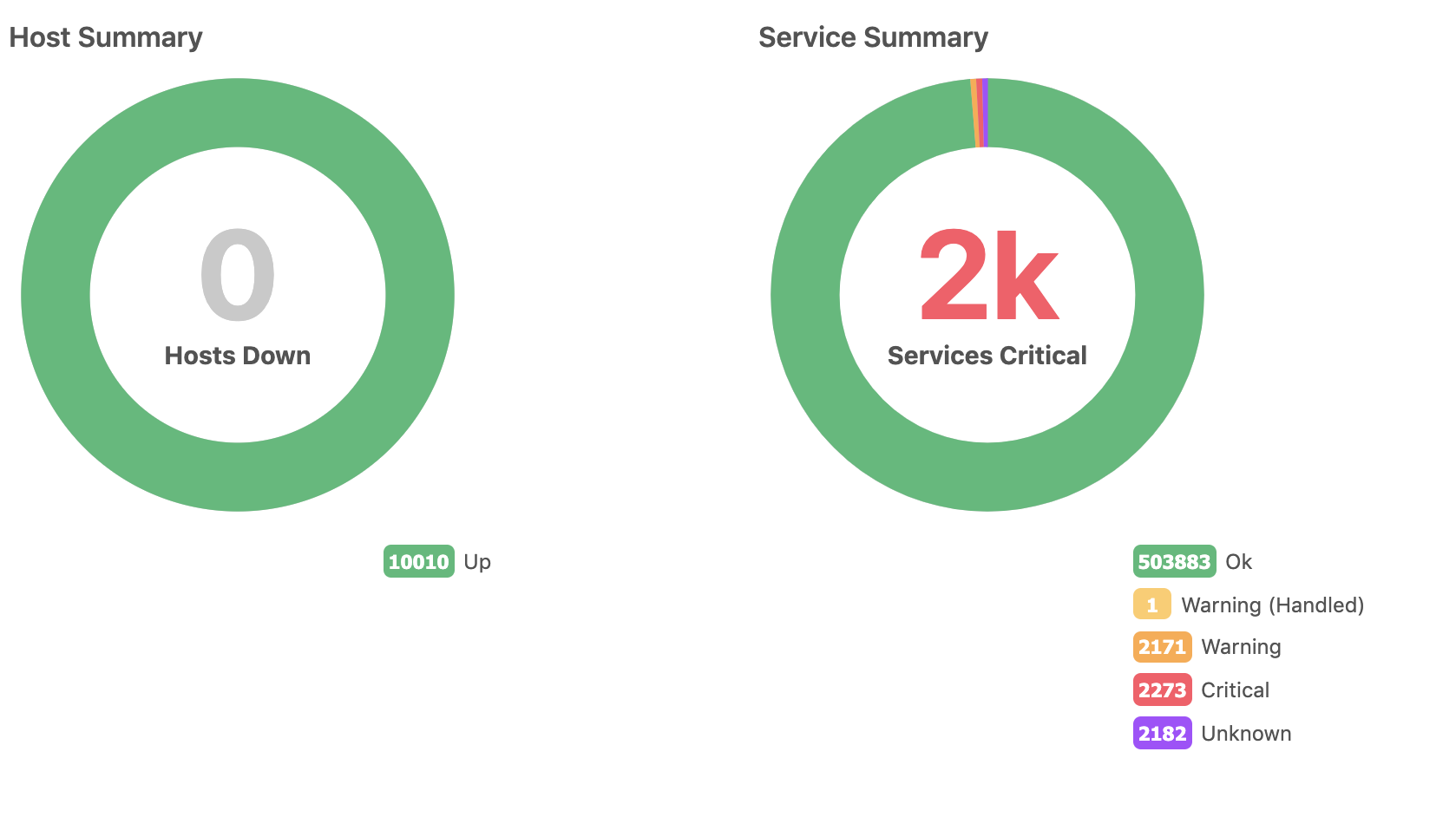
Works perfect with director, makes some offload from Master and i was able to keep all cluster alive at around 3000 Hosts, as a final step i configured 6000 Hosts(5000 events p/sec), Icinga2 app on Masters continue leaks with memory and still getting killed with OOM killer, but cluster continue working until satellites sends data in MySQL
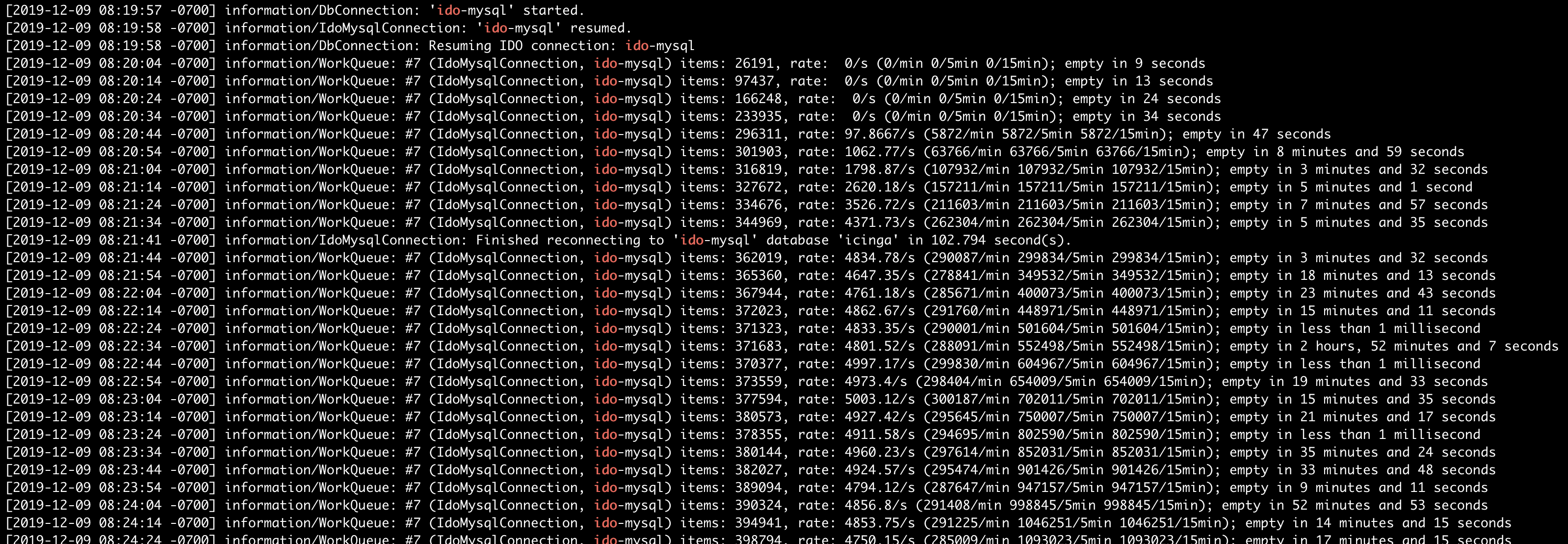
On Masters I disabled all icinga2 features and left only “api command mainlog” but it doesn’t help, in logs i can see messages like:
[2019-11-29 02:55:00 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1, rate: 5216.35/s (312981/min 312981/5min 312981/15min);
[2019-11-29 02:55:10 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 80304, rate: 7876.15/s (472569/min 472569/5min 472569/15min); empty in 9 seconds
[2019-11-29 02:55:20 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 179869, rate: 10479.8/s (628785/min 628785/5min 628785/15min); empty in 18 seconds
[2019-11-29 02:55:30 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 283860, rate: 13006.9/s (780414/min 780414/5min 780414/15min); empty in 27 seconds
[2019-11-29 02:55:40 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 399336, rate: 15455.5/s (927329/min 927329/5min 927329/15min); empty in 34 seconds
[2019-11-29 02:55:50 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 518236, rate: 13332.3/s (799938/min 1071679/5min 1071679/15min); empty in 43 seconds
[2019-11-29 02:56:00 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 637251, rate: 14938.8/s (896329/min 1211154/5min 1211154/15min); empty in 53 seconds
[2019-11-29 02:56:10 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 756500, rate: 14645.1/s (878709/min 1354390/5min 1354390/15min); empty in 1 minute and 3 seconds
[2019-11-29 02:56:20 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 879603, rate: 14372.7/s (862363/min 1493768/5min 1493768/15min); empty in 1 minute and 11 seconds
[2019-11-29 02:56:30 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1014816, rate: 13901.6/s (834096/min 1616707/5min 1616707/15min); empty in 1 minute and 15 seconds
[2019-11-29 02:56:40 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1140154, rate: 13726/s (823560/min 1753195/5min 1753195/15min); empty in 1 minute and 30 seconds
[2019-11-29 02:56:50 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1262784, rate: 13699.8/s (821989/min 1895614/5min 1895614/15min); empty in 1 minute and 42 seconds
[2019-11-29 02:57:00 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1383192, rate: 13746.4/s (824783/min 2038166/5min 2038166/15min); empty in 1 minute and 54 seconds
[2019-11-29 02:57:10 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1499154, rate: 13778.1/s (826688/min 2183558/5min 2183558/15min); empty in 2 minutes and 9 seconds
[2019-11-29 02:57:20 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1615627, rate: 13874.6/s (832476/min 2328664/5min 2328664/15min); empty in 2 minutes and 18 seconds
[2019-11-29 02:57:30 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1732766, rate: 14126.9/s (847616/min 2466894/5min 2466894/15min); empty in 2 minutes and 27 seconds
[2019-11-29 02:57:40 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1856457, rate: 14151.9/s (849114/min 2604760/5min 2604760/15min); empty in 2 minutes and 30 seconds
[2019-11-29 02:57:50 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 1975574, rate: 14228.4/s (853703/min 2751306/5min 2751306/15min); empty in 2 minutes and 45 seconds
[2019-11-29 02:58:00 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2094517, rate: 14195.5/s (851733/min 2892344/5min 2892344/15min); empty in 2 minutes and 56 seconds
[2019-11-29 02:58:10 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2212559, rate: 14104.3/s (846259/min 3032364/5min 3032364/15min); empty in 3 minutes and 7 seconds
[2019-11-29 02:58:20 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2342521, rate: 13928.9/s (835732/min 3166993/5min 3166993/15min); empty in 3 minutes
[2019-11-29 02:58:30 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2461257, rate: 13863.3/s (831796/min 3300993/5min 3300993/15min); empty in 3 minutes and 27 seconds
[2019-11-29 02:58:40 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2583046, rate: 13924.9/s (835495/min 3443022/5min 3443022/15min); empty in 3 minutes and 32 seconds
[2019-11-29 02:58:50 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2700537, rate: 13973/s (838377/min 3592124/5min 3592124/15min); empty in 3 minutes and 49 seconds
[2019-11-29 02:59:00 -0700] information/WorkQueue: #6 (ApiListener, RelayQueue) items: 2815752, rate: 14053.7/s (843222/min 3737734/5min 3737734/15min); empty in 4 minutes and 4 seconds
Seems like Icinga2 instance accepts messages faster than it able to drop them
Now i’m looking at way to disable sending check results messages to Master from Satellites, it will allow Master to be offloaded and be responsible only for API calls and Configuration distribution
@dnsmichi do you have any thoughts how to disable it?