UPDATE: Was able to re-IP my servers, they are now on the same subnet.
-
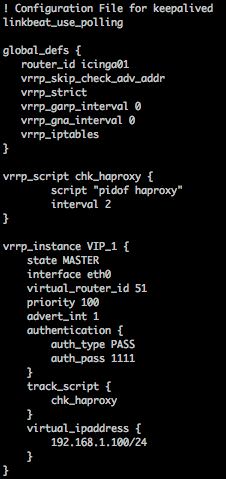
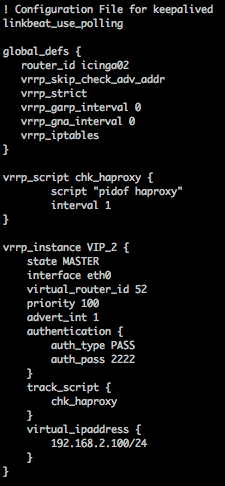
updated /etc/keepalived/keepalived.conf to match the example in this thread, now using Master/Backup blocks on each server.
-
updated /etc/opt/rh/rh-haproxy18/haproxy/haproxy.cfg to have both IP’s updated for Icinga2_ido & Icingaweb2_ido,
-
updated /etc/icinga2/zones.conf, /etc/icinga2/zones.conf/master/hosts.conf (for new IPs)
-
updated /etc/opt/rh/rh-mariadb103/my.cnf.d/galera.cnf (for new IPs)
-
updated /etc/opt/rh/rh-mariadb103/my.cnf.d/mariadb-server.cnf
-
rebooted, started a new galera_cluster instance, had 2nd master join…
Everything came online correctly, I am able to view HaProxy stats page. There are no errors in Icinga at this point.
To test this…
In vmware, I disconnect the vnic for Master2, I wanted to simulate a network disruptive event between 2 physical sites.
Expectation:
Master1 node should maybe hiccup and then connect to its local DB instance and keep chugging…
Result:
Master1 node assumes the VIP, ip addr show now has 3 ips.
I am getting a nice error in the Icinga GUI:
SQLSTATE[08S01]: Communication link failure: 1047 WSREP has not yet prepared node for application use, query was: SELECT CASE WHEN (UNIX_TIMESTAMP(programstatus.status_update_time) + 60 > UNIX_TIMESTAMP(NOW())) THEN 1 ELSE 0 END AS is_currently_running, programstatus.process_id, programstatus.endpoint_name, UNIX_TIMESTAMP(programstatus.program_start_time) AS program_start_time, UNIX_TIMESTAMP(programstatus.status_update_time) AS status_update_time, programstatus.program_version, UNIX_TIMESTAMP(programstatus.last_command_check) AS last_command_check, UNIX_TIMESTAMP(programstatus.last_log_rotation) AS last_log_rotation, programstatus.global_service_event_handler, programstatus.global_host_event_handler, programstatus.notifications_enabled, UNIX_TIMESTAMP(programstatus.disable_notif_expire_time) AS disable_notif_expire_time, programstatus.active_service_checks_enabled, programstatus.passive_service_checks_enabled, programstatus.active_host_checks_enabled, programstatus.passive_host_checks_enabled, programstatus.event_handlers_enabled, programstatus.obsess_over_services, programstatus.obsess_over_hosts, programstatus.flap_detection_enabled, programstatus.process_performance_data FROM icinga_programstatus AS programstatus
Unsure if this has any correlation:
sudo cat /mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: 2d859d0d-c2af-11e9-b811-d72f4992e5b7
seqno: -1
safe_to_bootstrap: 0