It’s time to continue my testing story with 2 additional tests
For comparison reasons i decided to make tests with Standalone Icinga2 Master instead of HA zone for masters. Satellite zones are still in HA mode.
Fourth test - In this test i followed official Icinga2 documentation, IDO feature enabled on Icinga2 Standalone Master only.
1 MySQL Database instance: CPU: x8(CPU MHz: 2394) RAM: 16GB
1 Masters in standalone mode, CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Satellites in HA (3 Satellite Zones), CPU: x8(CPU MHz: 2394) RAM: 16GB
6 Icinga2 Agents, 2 agents per each Satellite Zone, CPU: x4(CPU MHz: 2394) RAM: 4GB
Configuration schema:
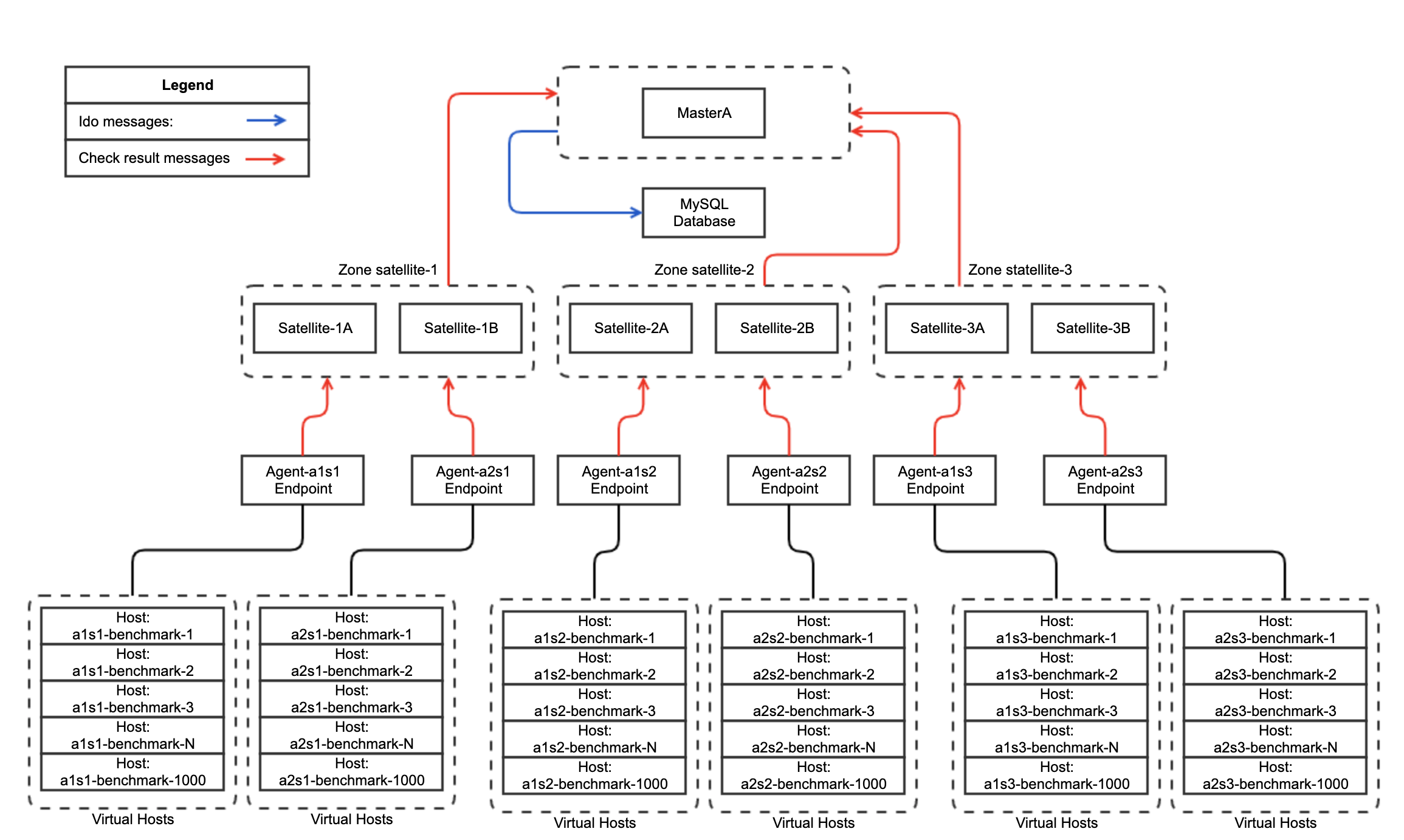
Test showed the almost same cluster performance as in Test 1 , Icinga2 master not able to utilize all resources and send all incoming check results to MySQL, it cause to huge IDO queues and finally deamon get killed by system OOM killer.
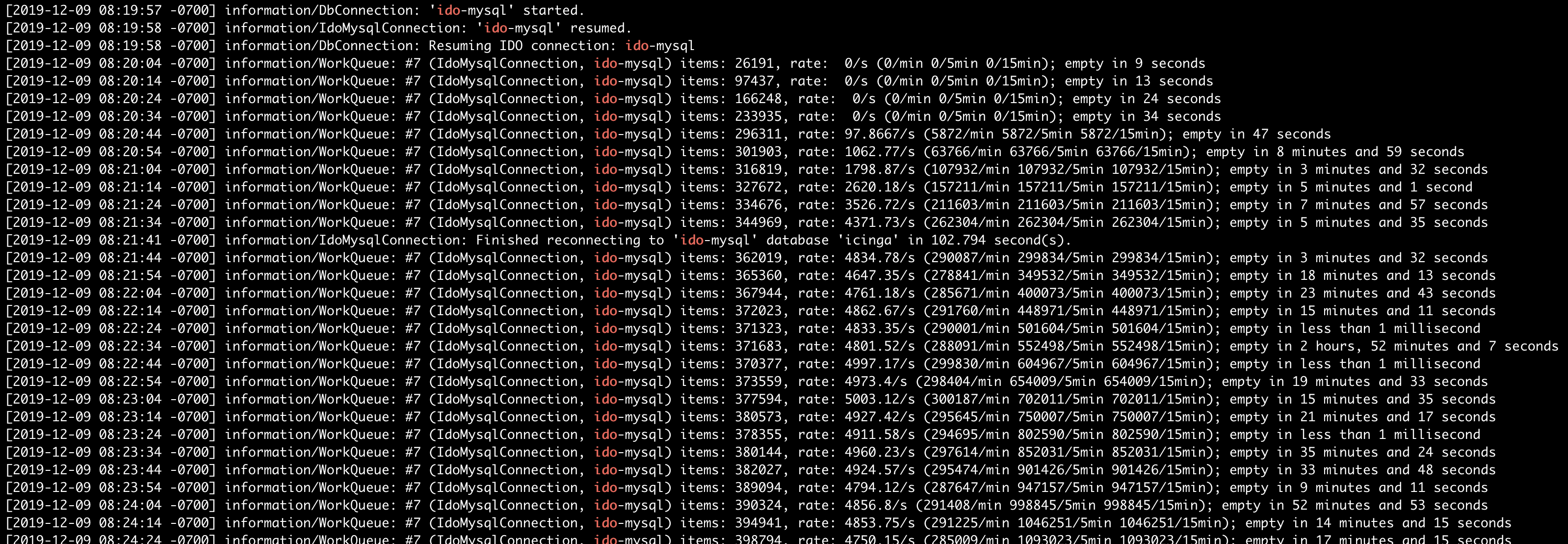
After 3000 hosts, Icinga2 Master not able to handle all incoming IDO queue.
Fifth test - configuration schema have the same logic as i described in Third test, IDO feature enabled on Icinga2 Satellite Endpoints.
Also i rebuild cluster with more Satellites.
1 MySQL Database instance: CPU: x8(CPU MHz: 2394) RAM: 16GB
1 Masters in standalone mode, CPU: x8(CPU MHz: 2394) RAM: 16GB
18 Satellites in HA (9 Satellite Zones), CPU: x8(CPU MHz: 2394) RAM: 16GB
18 Icinga2 Agents, 2 agents per each Satellite Zone, CPU: x4(CPU MHz: 2394) RAM: 4GB
Configuration schema example(naturally contain 9 satellite zones):
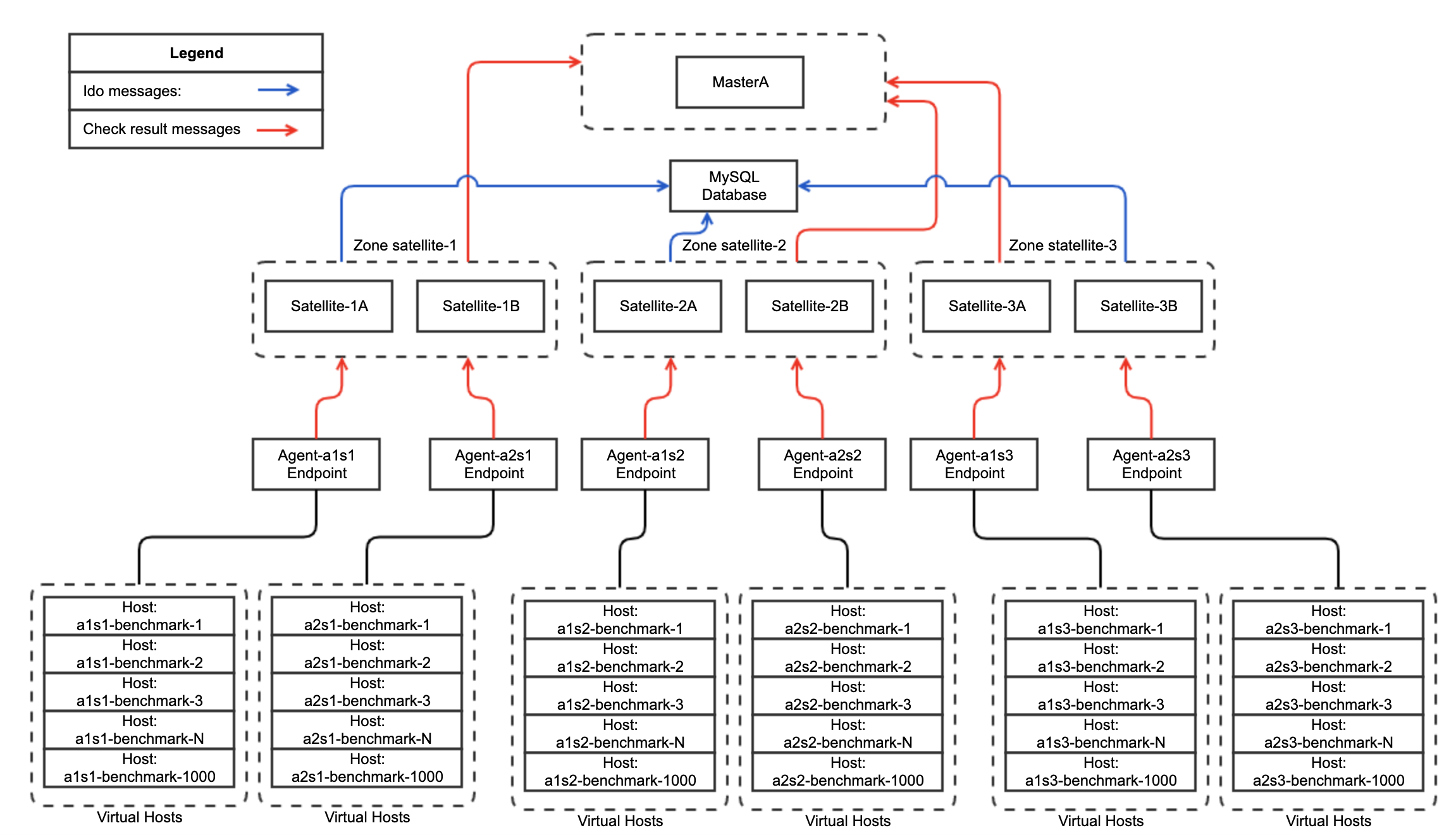
And here i have something really interesting to share:
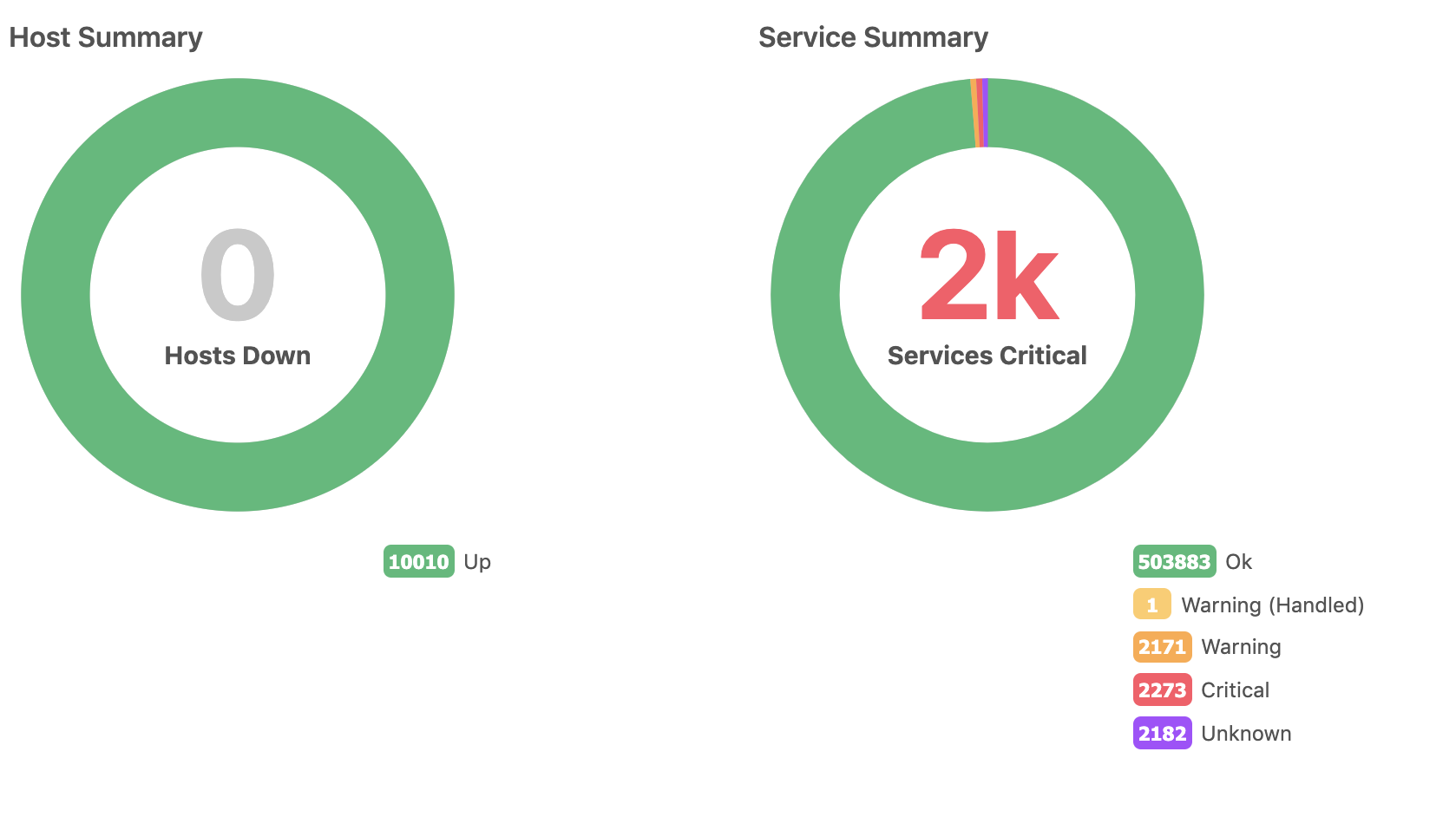
Have a first solid milestone in testing, 10k hosts, about 8400 events per second. Interesting founding that memory leaks stopped completely.
Here is RelayQueue logs:
[2019-12-12 06:24:02 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 1341, rate: 42606.6/s (2556396/min 12794928/5min 38846066/15min);
[2019-12-12 06:24:12 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 179, rate: 42690.1/s (2561407/min 12807613/5min 38914856/15min);
[2019-12-12 06:24:22 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 2, rate: 42512.4/s (2550745/min 12792016/5min 38937682/15min);
[2019-12-12 06:24:32 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 10, rate: 42540.4/s (2552425/min 12805184/5min 38961697/15min);
[2019-12-12 06:24:52 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 42, rate: 42437.2/s (2546230/min 12800608/5min 39000197/15min);
[2019-12-12 06:25:22 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 24, rate: 42100.5/s (2526029/min 12795742/5min 39073217/15min);
[2019-12-12 06:25:32 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 12, rate: 41916.2/s (2514970/min 12796443/5min 39074377/15min);
[2019-12-12 06:25:52 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 1, rate: 42035.8/s (2522148/min 12814652/5min 39099364/15min);
[2019-12-12 06:26:22 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 258, rate: 42451.9/s (2547115/min 12839445/5min 39172641/15min);
[2019-12-12 06:26:32 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 1, rate: 42479.3/s (2548759/min 12844078/5min 39203415/15min);
[2019-12-12 06:26:42 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 271, rate: 42487/s (2549220/min 12821474/5min 39210678/15min);
[2019-12-12 06:26:52 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 40, rate: 42239.2/s (2534349/min 12802741/5min 39196745/15min);
[2019-12-12 06:27:02 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 2, rate: 42231/s (2533858/min 12786579/5min 39141632/15min);
[2019-12-12 06:27:22 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 202, rate: 41704.4/s (2502264/min 12766433/5min 39016238/15min);
[2019-12-12 06:27:32 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 27, rate: 41635.7/s (2498142/min 12758562/5min 38964173/15min);
[2019-12-12 06:28:12 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 1, rate: 42651.8/s (2559105/min 12794018/5min 38824881/15min);
[2019-12-12 06:28:22 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 1, rate: 42846.8/s (2570810/min 12801761/5min 38791080/15min);
[2019-12-12 06:28:32 -0700] information/WorkQueue: #5 (ApiListener, RelayQueue) items: 5, rate: 42858.4/s (2571507/min 12788852/5min 38735522/15min);
Current rate of messages around 42k per sec, looks much better compared to 15k p/sec in third test.
Database iostat 5 minute statistics still looks good on this workloads.

Icinga2 Master workload:
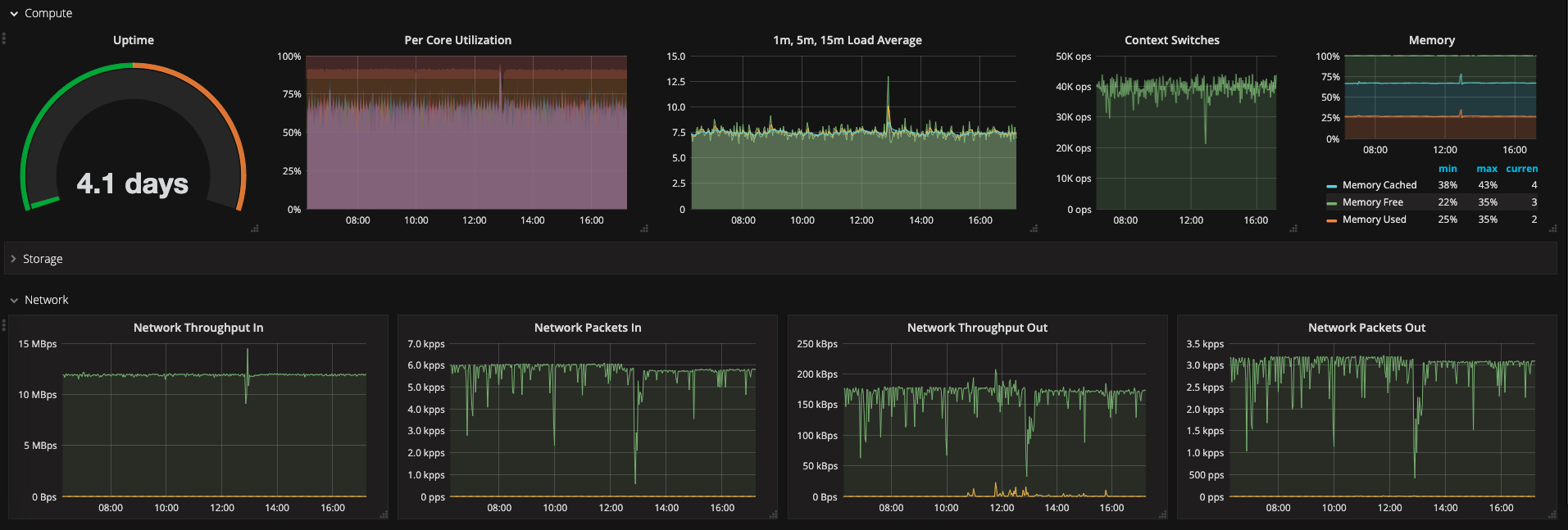
Icinga2 master regular workload ~8 LA, during configuration deployment we can track load spikes to 12-15 LA for the short term.
Configuration propagation in the system takes around 5-6 minutes, time calculated from pressing “Deploy” button in Director to getting hosts visualized in Tactical Overview with Pending status
Note: Current cluster limit is not reached and i’ll add more Hosts in current environment, currently want to track cluster stability.
P.S. Brief analysis show that we have:
- huge overhead on HA cluster work, standalone master (with not recommended config schema) handles at least 3 times more without memory leaks compared to HA mode with same schema
- low IDO queue utilization with Icinga2 process, not limited by system highload or MySQL performance