I’m confused about the state of monitored services when an agent times out. I’d like services to transition to unknown when the agent times out, but instead they’re keeping their last reported state.
I’ve configured cluster and cluster-zone checks as described here and the checks turn critical when communication with the agent is lost, but the services the agent monitors remain in their last state rather, than becoming unknown.
How can I make all services become unknown when the agent times out?
Thanks for the help! I’ve tried to duplicate your config, but I haven’t gotten it working yet.
Can you show me your Agent Health service config? That may be where I’m going wrong.
I’ve tried this from the docs, but the checks are unhandled and stuck in a pending state.
zones.d/master/services.conf
apply Service "Agent Health" {
check_command = "cluster-zone"
display_name = "cluster-health-" + host.name
/* This follows the convention that the agent zone name is the FQDN which is the same as the host object name. */
vars.cluster_zone = host.name
assign where host.vars.agent_endpoint
}
I’ve also tried a different version, which works on its own, but fails validation when I apply the service dependency with references a parent host/service which doesn’t exist.
zones.d/master/services.conf (names sanitized)
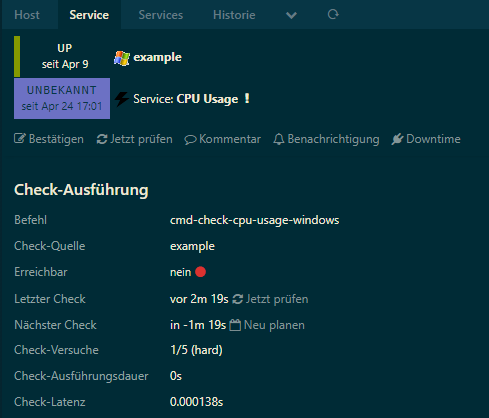
My services are now showing unreachable when the agent loses connectivity with the master. The state is still showing Ok, not unknown, but I suspect that’s a separate configuration problem.
I marked your response as the solution. Thanks again for your help, I really appreciate it!