Hi,
I ran into a strange behaviour, when I accidentally created a wrong downtime for a host and and tried to remove the downtime afterwards. The creation of the downtime object was not successful (says the API):
{
"results": [
{
"code": 500.0,
"status": "Action execution failed: 'Error: Function call 'localtime_r' failed with error code 75, 'Value too large for defined data type'\n'."
}
]
}
Although I can see the downtime in Icinga Web 2:
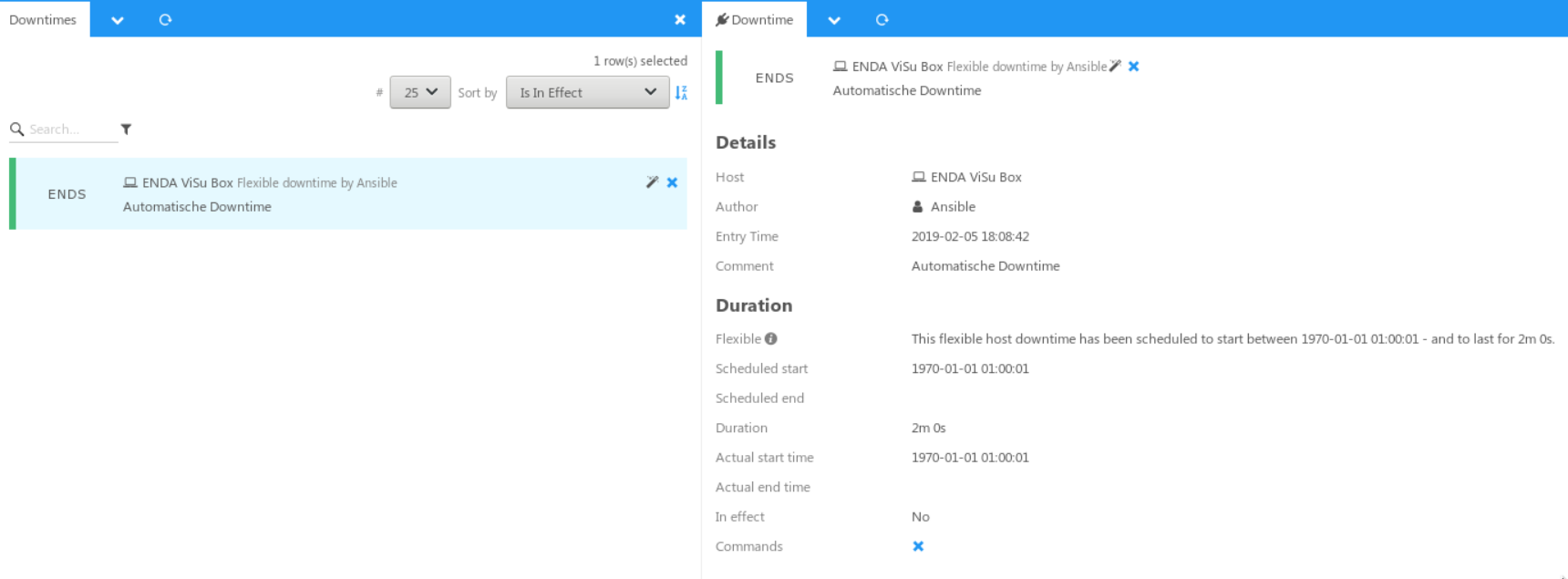
… but if I try to remove the Downtime, I get an error:
icinga2: Can't send external Icinga command: 404 No objects found.
Even if I try to remove all downtimes for this host by API, the broken downtime is still there.
Any ideas? Did I oversee something or is this a bug (which I should report)?
Environment
Icinga2 version: 2.10.2-1
OS: CentOS 7.6.1810