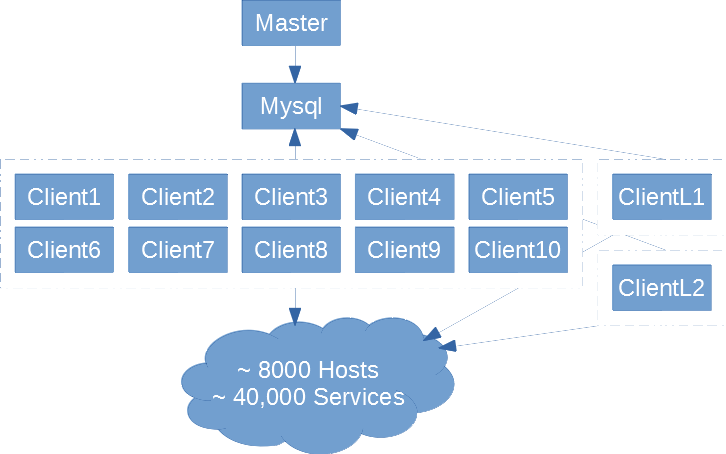
Checks are run on each host mostly each 5 min & using mostly SNMPIO (we are monitoring network devices only)
Currently we have set the max_current_checks to 128 be able to continue to use the server otherwise OOM kill the Icinga2 process.
So, due to the scheduled checks each minutes & the capacity of the farm, checks are not delivered on time. Sometimes with more than 600 sec of delay…
All pollers are at 0% CPU idle.
So maybe we are doing something wrong, or maybe it’s normal due to the load required.
I know also that more that 2 clients in a zone is not the best.
Can you suggest how to setup a better configuration ?
Does it mean VM cannot handle well that kind of job (they are each consuming more than 10Ghz) ?
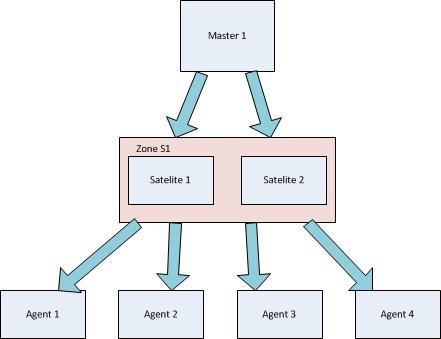
We tried to setup a Icinga2 topology with 3 level :
Master -> Satelitte -> Agent
But we failed to perform checks on agents. all checks were performed by the Satellite.
What are the requirements to have this kind of distributed topology ?
Do we have better performance and is the CPU consumption problem resolved ?
Is there any documentation about this kind of setup ?
We tried to setup a Icinga2 topology with 3 level :
Master → Satelitte → Agent
A very common arrangement.
But we failed to perform checks on agents. all checks were performed by the
Satellite.
What have you defined for command_endpoint for these checks?
What are the requirements to have this kind of distributed topology ?
See documentation below.
Do we have better performance and is the CPU consumption problem resolved ?
If you really do have exactly one master, one satellite and one agent, then I
don’t see the point of having the satellite.
However, assuming this is just a proof of concept, and that at some point the
master will have more than one satellite, and each satellite will have more
than one agent, this will distribute the load across your various machines
quite well.
If you never intend to have more than one satellite, why not just connect all
agent machines to the master?
Is there any documentation about this kind of setup ?
The terminology in your post maybe confusing some people. Please review the documents on a zone and zone object here.
A “Master”, “Satelitte” and “Agent” are all their own zones. They can be connected using the “parent” attribute. All endpoints in the same zone can communicate with each other only and can not communicate with other endpoints in other zones.
Please review the distributed monitoring page on how to configure a Icinga environment to match your infrastructure needs.
You can configure your host objects to use the “command_endpoint” attribute to configure which endpoint will run the check_command on the host. ( command_endpoint = host.name or command_endpoint = master(hostname) )
thanks for your answer. I’m sorry if I used wrong terminology I’ll try to be more precise.
I’ve read the distributed monitoring page and have already tested this kind of topology, the configuration was working correctly.
1 agent connected to 1 Satelitte connected to 2 endpoints which were in 2 differents zone: A1 and A2.
Every endpoints were fully operationnal.
Our problem was : How to import our devices, network equipments to have them correctly polled?
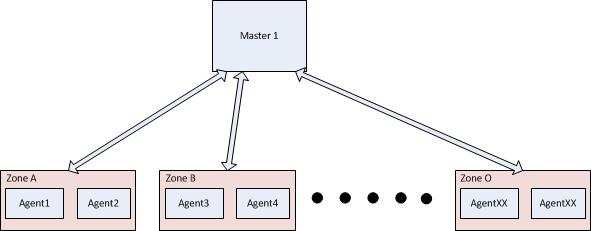
4 zones were configured :
M1 - with Endpoint : master
S1 - With Endpoint : Satelitte and Parent : M1
A1 - With Endpoint : Agent 1 and Parent : S1
A2 - With Endpoint : Agent 2 and Parent : S1
To monitor our devices, we imported them and configured them into specific zone because we have a lot of legacy work.
And this is not the way to work with distributed topology, I’ve found our problem.
But we still have 3 questions :
Does it mean VM cannot handle well that kind of job (they are each consuming more than 10Ghz) ?
Do you confirm that having more than 2 endpoints is causing the high CPU consumption ?
What is the best way to exclude some poller to execute checks on specific hosts?
I believe you can use the Icinga director module to import all your devices. I am not using director, so I can not 100% confirm this. I added all my devices by conf file. I had this same problem when I upgraded from Icinga 1. I had to manually move all data from Icinga 1. It took a long time because I had to confirm each host was assigned to the same hostgroups and the same contacts was notified. I wrote a small script to speed up the import process. This script created a new conf file for each host per hostname / IP address.
Your server should be able to handle the load. I currently monitoring 1.5k+ hosts and 10k+ services and my server load is very low.
Have you reviewed your debug logs yet to see if you notice any problems that could cause the extra load?
Check Performance depends mainly on your check. What snmp check are you using?
Do not use more than two Endpoints in one zone, as far as i know its not official supported yet and has performance impacts.
This one I do not understand. What is a Poller? A Satellite/endpoint? You can distribute checks to separate zones with the “zone” parameter for a host (the thing you want to check). I would not recommend to define a command_endpoint to execute the check on a specific Endpoint. Just let icinga decide which endpoint in a zone should execute the check. But don’t add more than two nodes to a zone
So the way to go in my opinion: If your Endpoint is reaching 100% because of Check CPU usage (NOT Icinga load) simply add another zone and move some hosts to this zone.
Following your advices and your comments, we rebuilt our Icinga2 infrastructure and the way we use director to import our devices.
We configured director to affect dynamicly our network devices in a zone to have a dynamic loadbalancing between the zones.
To answer your questions, we are using mostly homemade script (perl, bash, python) to monitor our network devices and check_nwc_health plugin (https://github.com/lausser/check_nwc_health)
We saw the decrease of the CPU usage on all our endpoint immediatly after the change.
check_nwc_health has a realy high ressource consumption, compared to other checks. The compiled version is 3mb of size and has 77k lines of code. It also writes perffiles for calculation etc. for every check. I get a boost by writing the perffiles to ramdisk and using ssd for the systems.
We are still using it for most snmp checks, because @lausser has done a great job detecting all the anomalies, collecting all necessary values and calculating them in to meaningful data.
But keep in mind that its not the check to use if you have performance optimization in mind
Just to be sure: Is the load coming from the checks or from icinga2?
btw. we only cluster the master. All satellites are standalone instances where we deploy the hosts by templates and move them if the satellite has to much load. I try to keep the environment as simple as possible.
At the beginning, we suspected check_nwc_health to be the root cause of our server overload but it was related to our configuration…
1 of our objective is to replace check_nwc_health by home made script (only for easy cases we can handle with other tool or snmp )
I checked and I confirm that the load is coming from the checks (=> Perl process => check_nwc_health)
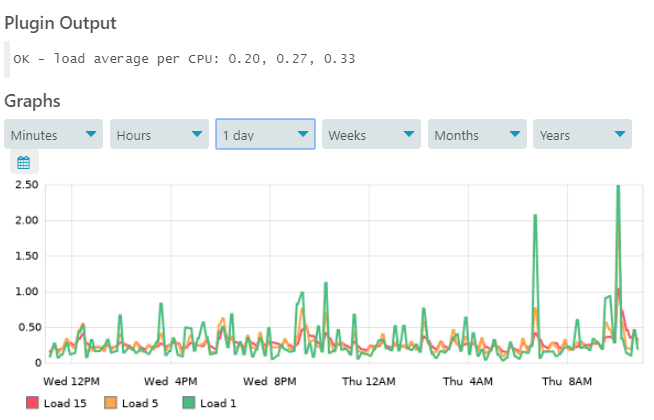
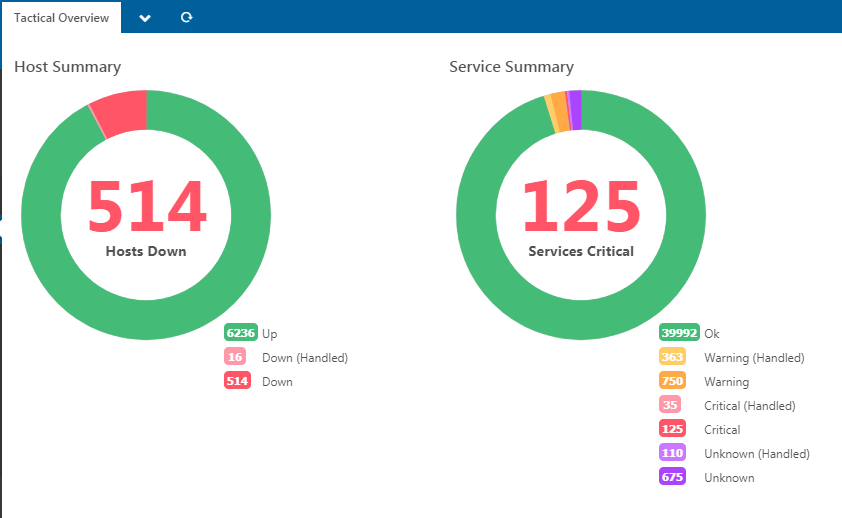
Graphic is showing the CPU Idle, so our endpoint is between 10-30% CPU usage, which is quite better than 0% IDLE
We configured the satelitte in standalone mode to have redundancy in the checks in case of problem. How do you handle the crash of 1 satelitte ?
Do the modification of the template is automatic ?
I don’t have any satellite server in my configuration. I have 2 master server in my configuration and I would guess the satellites act the same way as master servers. If I stop the Icinga2 service on one of my master servers all checks that were running on the now offline master server automatically move over to the online master server without a problem. I would say that the satellite will act the same way.
We are using VMs for the satellite. I have never seen a Icinga/linux system crashing despite of configuration errors or hardware errors. The hardware error is solved by vm and if not, we trust in our backupsystem
If a satellite is down, we can move checks to another satellite if no firewall prevents it.
We accept the risk of a small downtime (restore from backup f.e.) in this “never happend to us”-case.
We have a template for each satellite which we add to the host. Its not automatically, but its set on host creation at deployment. To change the satellite we bulk edit with director or use the api. The performance of a Satellite is only rising if we add more services, so it will never happens without adding checks.