So I used stress on a vm connected to the master node running icinga to force the node into a crtical state for cpu usage
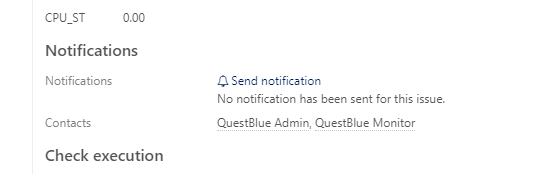
I waited about 30 mins and have not received a notification, It says below notification No notification has been sent for this issue.
Here are my configurations
notifications.conf
apply Notification "notify-once" to Service{
import "mail-service-notification"
users = [ "monitor" , "admin" ]
interval = 5m
assign where service.name == "Ping"
}
I have repeated this in the same file for every service
users.conf
object User "admin"{
import "generic-user"
display_name = "<removed for security purposes> Admin"
enable_notifications = true
states = [ Warning, Critical, Unknown ]
types = [ Problem, Acknowledgement, Recovery, Custom, FlappingStart,
FlappingEnd, DowntimeStart, DowntimeEnd, DowntimeRemoved ]
email = "<removed for security purposes>"
}
I am not sure where to go from here in order to get notifications work. I know that the mail server is working correctly because I can go to the notifications tab and send out a custom message but it is not automatically sending the notifications.
Please advise on where I should go from here