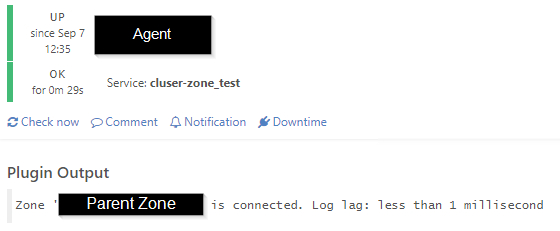
I am currently hesitant to deploy the Icinga Agent because I have observed the following problem. A few agents were rolled out on a test basis and intentionally misconfigured. For example, only one parent (satellite) was configured where there are two. The agent successfully connects to the parent, however I get the following error in Icinga:
Remote Icinga instance 'Child' is not connected to 'Sat1'.
The client, on the other hand, has successfully connected to Sat2:
2021-09-07 08:48:42 +0200] information/ApiListener: Reconnecting to endpoint 'Sat2' via host 'Sat2' and port '5665'
2021-09-07 08:48:42 +0200] information/ConfigItem: Activated all objects.
2021-09-07 08:48:42 +0200] information/ApiListener: New client connection for identity 'Sat2' to [1.2.3.4]:5665
2021-09-07 08:48:42 +0200] information/ApiListener: Requesting new certificate for this Icinga instance from endpoint 'Sat2'.
2021-09-07 08:48:42 +0200] information/ApiListener: Sending config updates for endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished sending config file updates for endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Syncing runtime objects to endpoint 'Sat2'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished syncing runtime objects to endpoint 'Sat2'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished sending runtime config updates for endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Sending replay log for endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished sending replay log for endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished syncing endpoint 'Sat2' in zone 'ZoneA'.
2021-09-07 08:48:42 +0200] information/ApiListener: Finished reconnecting to endpoint 'Sat2' via host 'Sat2' and port '5665'
2021-09-07 08:48:42 +0200] information/ApiListener: Applying config update from endpoint 'Sat2' of zone 'ZoneA'.
I would expect that in this case Icinga would route the check results to the master via Sat2, which unfortunately is not the case. I realize that normally both parents should be reachable, but this is something I can’t guarantee. I built the redundancy to have a working monitoring in such a case, where the connection to a single satellite is disturbed.
Give as much information as you can, e.g.
-
Version used (
icinga2 --version)
2.13.1 -
Operating System and version
Centos 7 (Master) Centos 8 (Satellite) Windows 2016 (Agent) -
Enabled features (
icinga2 feature list):
Disabled features: command compatlog debuglog elasticsearch gelf graphite icingadb influxdb2 opentsdb perfdata statusdata syslog
Enabled features: api checker ido-mysql influxdb livestatus mainlog notification -
Icinga Web 2 version and modules (System - About)
2.9.3 -
Config validation (
icinga2 daemon -C) -
If you run multiple Icinga 2 instances, the
zones.conffile (oricinga2 object list --type Endpointandicinga2 object list --type Zone) from all affected nodes