We are facing problems with one of our icingadb where the DB is growing with no end.
The Icinga2 Instance is not that big:
Hosts: ~1600
Services: ~17000
But the Icingadb is growing so that we reaching absurd sizes:
[root@icinga ~]# du -sh /var/lib/mysql/icingadb/
167G /var/lib/mysql/icingadb/
Inside the /etc/icingadb/config.yml the retention option is set to 30 days, but it keeps growing.
From time to time we clean up the DB manually but this is nothing we want to do every 1-2 months.
Does anyone else expirienced such an issue and maybe have an solution for this?
About the environment:
This is an HPC Cluster that is not 100% productive right now.
So we have a lot of systems that are offline but they have a downtime set in Icinga.
We have another cluster that we monitoring with icinga2, where we do not facing those issues.
Icinga DB Web version: 1.0.2
Icinga Web 2 version: 2.11.4
Web browser: Chrome 113
Icinga 2 version: r2.13.7-1
Icinga DB version : v1.1.0
PHP version used : 7.2.24
Server operating system and version: Rocky Linux release 8.8 (Green Obsidian)
You don’t seem to have any retention configured (only for the logging of the retention). Have a look at the configuration docs. There is also a config.example.yml
I updated the config.yml with an retention of 30 day.
So, I will give the icingadb some time and check back if there is some cleanup made.
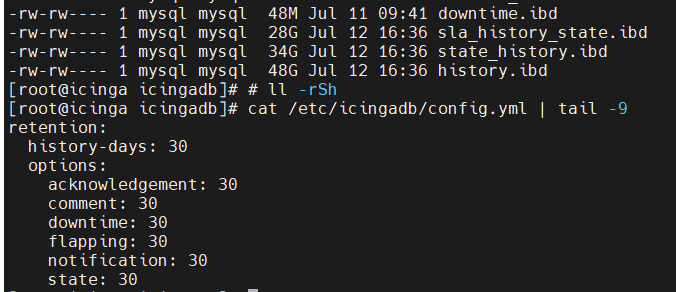
The actual status of the db files are:
# ll /var/lib/mysql/icingadb/ -Srh | tail
-rw-rw---- 1 mysql mysql 18M Jun 7 19:53 sla_history_downtime.ibd
-rw-rw---- 1 mysql mysql 18M Jun 14 10:04 downtime_history.ibd
-rw-rw---- 1 mysql mysql 23M Apr 17 10:32 service.ibd
-rw-rw---- 1 mysql mysql 26M Jun 7 15:18 service_customvar.ibd
-rw-rw---- 1 mysql mysql 36M Jun 7 16:18 host_customvar.ibd
-rw-rw---- 1 mysql mysql 36M Jun 7 21:15 downtime.ibd
-rw-rw---- 1 mysql mysql 40M Jun 14 10:06 service_state.ibd
-rw-rw---- 1 mysql mysql 13G Jun 14 10:06 sla_history_state.ibd
-rw-rw---- 1 mysql mysql 21G Jun 14 10:06 state_history.ibd
-rw-rw---- 1 mysql mysql 22G Jun 14 10:06 history.ibd
Hi @pbirokas, just curious, did you restart the icingadb service after changing the config file? If so, you can set the log level for the retention component to debug as well and see what icingadb is doing.
Everything looks fine for almost all history types except sla_downtime and sla_state. You have not set the retention for SLA and thus by default it is kept forever.
retention:
# Number of days to retain historical data for SLA reporting. By default, it is retained forever.
# sla-days:
I added those two into the config file, but now the icingadb stop from time to time:
Jul 18 15:42:49 icinga icingadb[132922]: Error 1206: The total number of locks exceeds the lock table size
can't perform "DELETE FROM sla_history_state WHERE environment_id = :environment_id AND event_time < :time\nORDER BY event_time LIMIT 5000"
github.com/icinga/icingadb/internal.CantPerformQuery
github.com/icinga/icingadb/internal/internal.go:30
github.com/icinga/icingadb/pkg/icingadb.(*DB).CleanupOlderThan
github.com/icinga/icingadb/pkg/icingadb/cleanup.go:53
github.com/icinga/icingadb/pkg/icingadb/history.(*Retention).Start.func1
github.com/icinga/icingadb/pkg/icingadb/history/retention.go:189
github.com/icinga/icingadb/pkg/periodic.Start.func1
github.com/icinga/icingadb/pkg/periodic/periodic.go:78
runtime.goexit
runtime/asm_amd64.s:1594
Jul 18 15:42:49 icinga systemd[1]: icingadb.service: Main process exited, code=exited, status=1/FAILURE
Jul 18 15:42:49 icinga systemd[1]: icingadb.service: Failed with result 'exit-code'.
Hii, that’s an Icinga DB bug. Please open an issue here, but till this gets fixed and released may take a while. Try if changing the innodb buffer pool size to a higher value helps.