I need to monitor a service (TSM) that is running with a floating IP on one of two hosts. Clients access the service through its floating service IP address.
Now, when I configure the service to monitor through the host address, everything works fine - but will not cover the failover to the other host.
When I configure the service to monitor through the service IP address, it says the Icinga Instance (the agent) is not connected to the Icinga2 server. Now, thats true.
Thing is, I also want to monitor the hosts, they also got services like cup, file systems etc.
Any idea how to deal with this? Maybe register the same Icinga2 Agent with two names?
As an idea:
Is it possible to add a separate/independent IP to each of the hosts and use this for monitoring purposes?
This would avoid problems resulting of usage of the floating IP (VIP).
The service itself - or the failover process - could me monitored otherwise.
Most likely the Host will respond with it’s own IP and not with the floating one. This is at least the case for SNMP monitoring a Windows Cluster. The firewall at your icinga server will drop such packets. Try it with disabled firewall.
Hello @danielbierstedt,
I have experienced this same problem when monitoring Windows Clusters. I added the cluster nodes and can monitor them using the normal Icinga agent. I can NOT monitor the cluster virtual node (different FQDN address than nodes) using the Icinga agent.
The only solution I have found to monitor the cluster virtual node was by using the check_nrpe check command. I know this check command is not secure but I don’t know of another solution. I am also interested in a secure solution to this problem.
Security is a big word here, so I cannot choose anything that is not encrypted, has no authentication etc.
I’ll leave it as is for now, but I don’t like it. Maybe I switch to check execution by SSH sometime, if necessary. Thats not what I want, espacially with Firewalls to deal with, but lets see.
you could use the nsclient++ api to push nrpe/nscp requests throught, it supports authentication and encryption, but i’m not good enought in security to tell you if it’s a fully reliable.
You could setup the services as passive service - so icinga will just sit & wait to receife results (with a threshold time to go to warning when there was no new status within specified time)
And then do the checks direct on the system (i.e. in bash or powershell) and forward the check results to icinga via API
I do similar with checks if daily backup was successfull on my internet servers.
I would do the monitoring of the floating IP from a host which actually would like to connect to that IP or (as an alternative) execute the check on the icinga master instead of the host the application actually runs on. That implicitly also checks the firewalls in between, so I would make sure to check the application on all hosts in the cluster and on top the access over the network.
I also found, that the usual tcp_port check of icinga produces log entries about failed connects, incomplete logins etc.Those then pop up in your log files (which you might also monitor). So, for most of our applications, we developed custom checks which are actually able to not only check the port but also ensure that a session could be established and the monitoring user could log in. Or, if there is a REST API with a status URL behind that port, use the http and/or json check.
I would like to revive this topic. @danielbierstedt could you please give a short summary how you solved this problem?
I also try to monitor linux based servers which have a floating IP (i.e. pacemaker with cluster IP).
The problem is, the servers need to be monitored on the primary (not floating) IP, too.
My best suggestion by now is to set up a second systemd-Unit for icinga2 with its own config (i.e. its own /etc/icinga2_second_instance/ , /var/lib/icinga2_second_instance/ etc.).
But I really would like to know any other ideas for executing plugins locally on the icinga agents.
Very sorry, I did not solve the problem. At some point I decided that the outcome is not worth the effort and kept switching manually whenever needed. Luckily this was a rare situation.
I monitor physical servers with floating IP addresses and associated services
(for example Asterisk, Apache, FreeSwitch, OpenVPN).
I do this by defining one Icinga endpoint per physical server plus one endpoint
per virtual IP.
I then monitor services which are expected to be running on the physical
server, whether it has the floating IP at that time or not, on the physical
server endpoint.
I monitor the services which move with the floating IP on the floating endpoint.
Thus if I have two servers with one floating IP, Icinga shows three hosts being
monitored, two of them for the services which run all the time, and one for
the services which float.
A single instance of Icinga on each physical server can respond to the service
requests initiated from the master / satellite parent instance, no matter
whether the checks are for the “real” or the floating IP host.
I also use 3 hosts for the 2 hosts with a floating IP plus a bit of DSL magic on the floating host to make sure that only one host has exclusive services running.
There’s also a version of the same code, that requires the service is running on both hosts.
I think, I understand your approach, let me clarify to verify that
My current goal is to execute all checks locally on the agent, only via icinga-agent. That means no check_by_ssh, no check_nrpe.
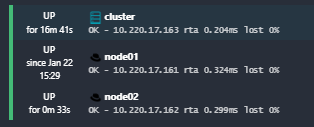
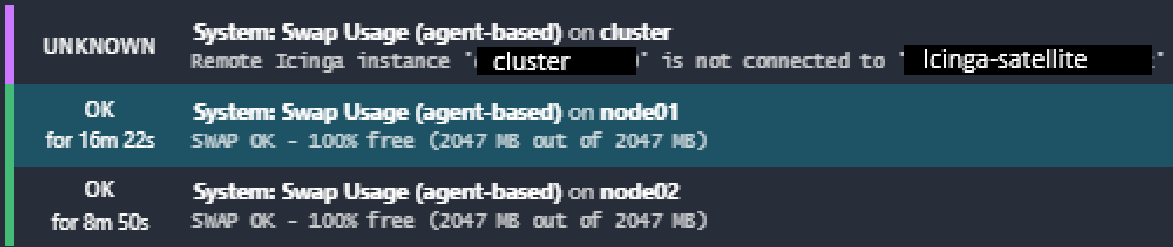
I am testing with the check_swap which is executed locally by the icinga-agent on the host-object “cluster”.
“cluster’s” IP is currently mapped on node01, but the icinga-agent config on that host is configured as NodeName=“node01”, not NodeName=“cluster”.
As the NodeName (Configured in /etc/icinga2/constants.conf) of the host-object is not “cluster” but “node01” at the moment, the icinga-agent running on the icinga-satellite can not connect to the icinga-agent Endpoint running on “cluster”. This is shown in the following screenshot
Either I am doing something wrong in the current configuration or we talk past to each other
@rivad I agree with you that using the dummy command or the “let the icinga-agent send checkresults to a passive check” is a solution, but that is not the kind of way that suits our case.
I am currently testing with the “second icinga2 instance” I proposed by starting a second systemd-unit which is actively running on all nodes of the cluster.
@Tqnsls there are, no passive checks involved in this setup.
The dummy check I use there is specially build for me by the Linuxfabik.
Reason was that the only place one can use the DSL with the director is in Check arguments and this dummy just reflects the results back into Icinga2.
I use this special checks on the floating IP’s host object to aggregate the results form the actual checks on the real hosts, checked via agent, bound to services with the same name.
@rivad Ah, now I understood your concept
We are using the similar approach with the businessprocesses but yours is more comfortable and has no overhead with the businessprocess-nodes.
Thank you very much for your input, I will take a deeper look into it now.
I think I would add a warn state for our case tbh