Hi,
We have Icinga2 version 2.6.2 deployed to monitor our infrastructure.
We noticed the other day that for some hosts the “check source” of the host check, is the machine itself, meaning the machines always appear to be up, even when they’re down, as no check results get back to the master.
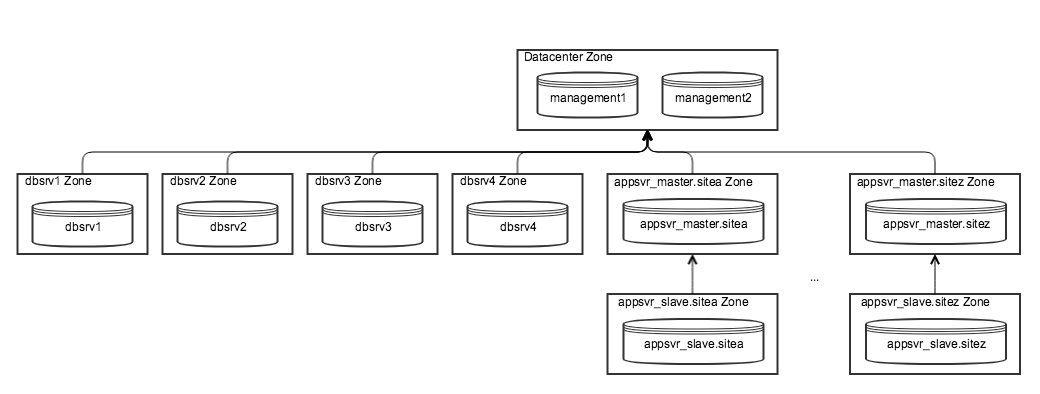
We use a cluster of two nodes for high availability in a “datacenter” zone, which is the master zone…I don’t know why it isn’t called that unfortunately…before my time :-(.
We have several other machines in the datacentre, each in their own zone as a child of datacenter zone, located alongside the machines hosting icinga2.
We have several remote sites. Each site has a pair of machines, a “master” machine which is in it’s own zone, a satellite of the datacenter zone. Alongside a “slave” machine which again is in it’s own zone, as a client of the zone of its corresponding “master” machine.
The two main icinga servers correctly check one another. Likewise they share the task of checking the other data center servers between themselves.
The satellite nodes from the datacenter correctly check their notional subordinate node.
However the satellite node for some reason also checks itself, rather than one of the icinga nodes in the datacenter zone as I would have expected.
I’ve checked that the zone hierarchy is defined correctly and that there’s definitely a network route from the icinga masters in the datacentre zone to the satellite node but other than that am a bit lost.
Graphically this arrangement is as follows:
An extract of our zones.conf file follows, with IP addresses and FQDN’s redacted where required.
# GLOBAL ZONES
object Zone "global-templates" { global = true }
object Zone "global-commands" { global = true }
################################################################################################################
# Icinga master zone endpoints
object Endpoint "management1.<REDACTED>" { host = "x.x.x.x" }
object Endpoint "management2.<REDACTED>" { host = "x.x.x.x" }
# Icinga master zone
object Zone "datacenter" { endpoints = [
"management1.<REDACTED>",
"management2.<REDACTED>",
] }
################################################################################################################
# Datacentre zone endpoints
object Endpoint "dbsrv1.<REDACTED>" { host = "x.x.x.x" }
object Endpoint "dbsvr2.<REDACTED>" { host = "x.x.x.x" }
object Endpoint "dbsvr3.<REDACTED>" { host = "x.x.x.x" }
object Endpoint "dbsvr4.<REDACTED>" { host = "x.x.x.x" }
# Datacentre zones
object Zone "dbsrv1.<REDACTED>" { endpoints = [ "dbsrv1.<REDACTED>" ] ; parent = "datacenter" }
object Zone "dbsvr2.<REDACTED>" { endpoints = [ "dbsvr2.<REDACTED>" ] ; parent = "datacenter" }
object Zone "dbsvr3.<REDACTED>" { endpoints = [ "dbsvr3.<REDACTED>" ] ; parent = "datacenter" }
object Zone "dbsvr4.<REDACTED>" { endpoints = [ "dbsvr4.<REDACTED>" ] ; parent = "datacenter" }
################################################################################################################
# Remote satellite zone endpoints
object Endpoint "appsvr_master.sitea.<REDACTED>" { host = "x.x.x.x" }
# Remote satellite zones
object Zone "appsvr_master.sitea.<REDACTED>" { endpoints = [ "appsvr_master.sitea.<REDACTED>" ] ; parent = "datacenter" }
################################################################################################################
# Remote client zone endpoints
object Endpoint "appsvr_slave.sitea<REDACTED>" { }
# Remove client zones
object Zone "appsvr_slave.sitea.<REDACTED>" { endpoints = [ "appsvr_slave.sitea.<REDACTED>" ] ; parent = "appsvr_master.sitea.<REDACTED>" }
Could anyone help me shed some light on what might be the problem here?
Thanks,
Phil

 .
. .
.