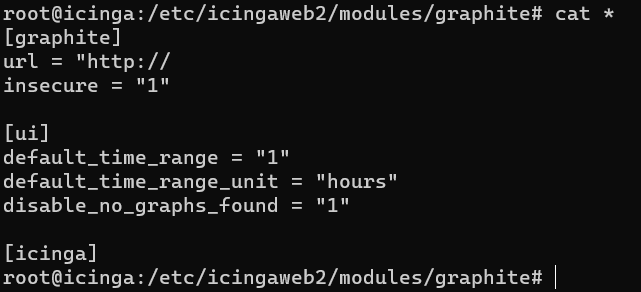
One idea is, that you have a graph setting within the icingaweb2 templates directory (/etc/icingaweb2/modules/graphite/templates/ (default-path)) which affects especially this graph.
It’s a long time since I used Carbon and Graphite but is the graph ok in Graphite?
Maybe the cpu files for this retention got corrupted - try to export the datapoints on the cli.
If I troubleshoot something, I try to divide the problem space roughly in the middle and device checks to figure out which half is OK and which isn’t. If you repeat this, the problem space gets smaller and smaller until the bug/error can’t hide any longer.
If I remember correctly carbon files can be stuck in a bad configuration and need to be rebuild for new retention to take effect.
You still watch the problem trough the whole stack and only learned, that it isn’t host but service dependent. Can you try to dissect the stack by having a look directly in Graphite?
If the problem exists there as well, we know it isn’t the icingaweb2 graphite module.
Then it still can be the writer or the carbon db.
Dominik you’re right in what you say,
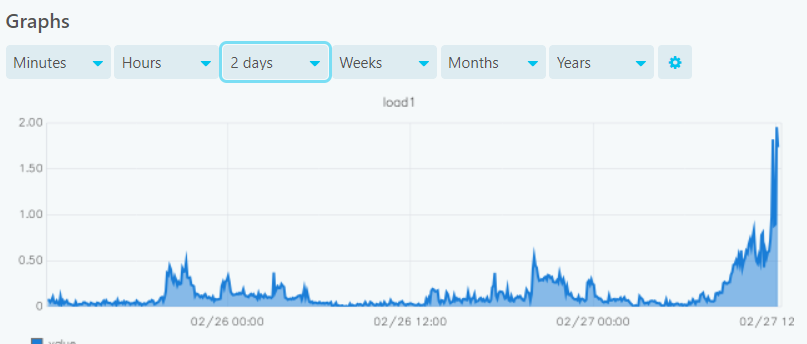
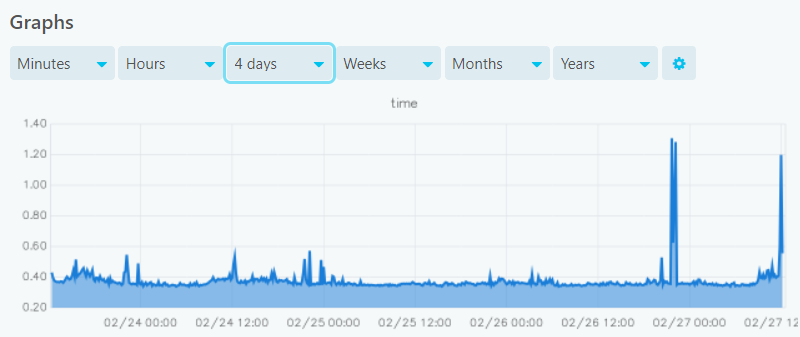
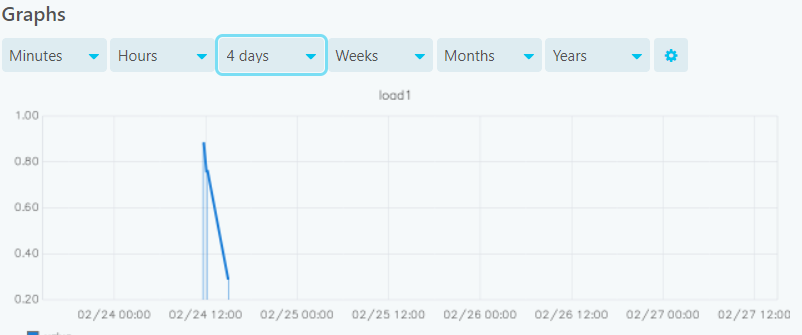
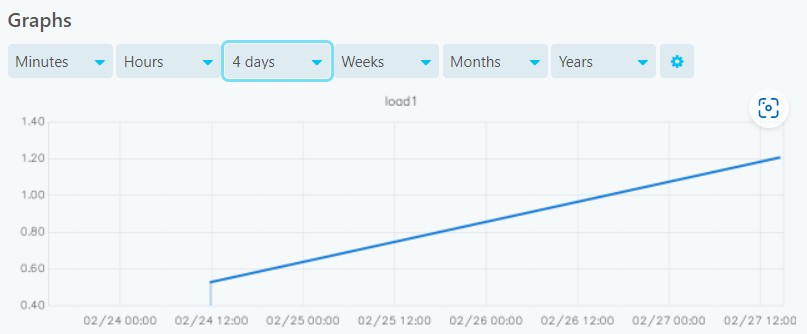
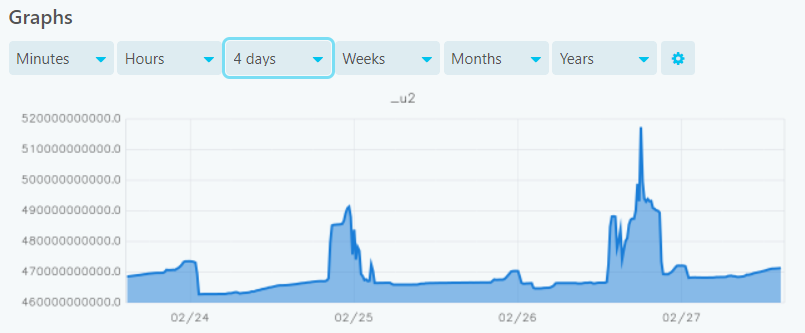
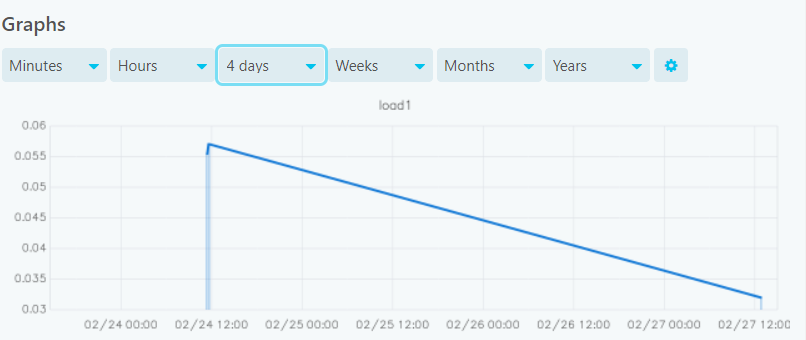
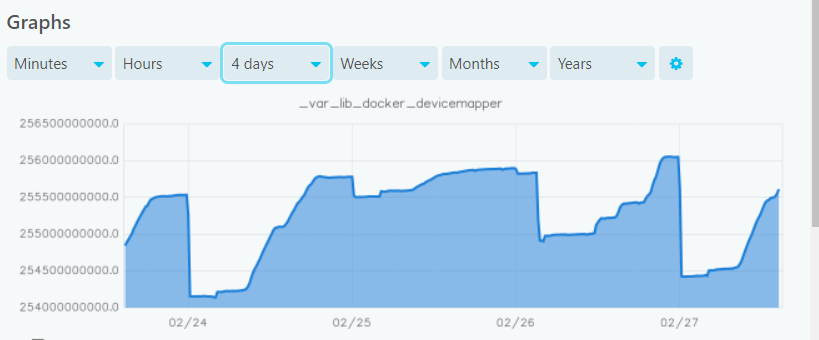
If I go to graphite-web i can see only data for the last 2 days. Nothing before gets saved.
But all my services are configured equally and only this one doesn’t work correctly dunno why
Recheck the configuration and then there was a command to apply/reapply the retention config to the carbon files. I guess, you have enough free space and inodes?
Also look it there are carbon logfiles with errors or maybe it logs into syslog.
So your check interval is 5 minutes.
This might not be enough, depending on the xFilesFactor, for checks to get stored longer than 2 days.
Please see here: Funky link
good point!
check your storage-aggregation.conf for that setting.
here is another explanation:
be aware that changes to both files (storage-schemas and storage-aggregation) only take effect on new archives, unless you do a whisper-resize on the exisiting ones.