Hi Everyone,
I noticed weird behaviour (or it is my mistake somewhere) with Scheduled Downtime, i.e. I have something like that configured in Icinga Director → ScheduledDowntime Apply Rules:
zones.d/tmg_master/scheduled_downtime_apply.conf
apply ScheduledDowntime "process-trade-container-server" to Service {
author = "xxx"
comment = "Scheduled Downtime for process trade_container_server"
fixed = true
assign where match("process trade_container_server*", service.name)
ranges = {
"friday" = "16:00-16:35"
"monday" = "16:00-16:35"
"saturday" = "16:00-16:35"
"sunday" = "16:00-16:35"
"thursday" = "16:00-16:35"
"tuesday" = "16:00-16:35"
"wednesday" = "16:00-16:35"
}
}
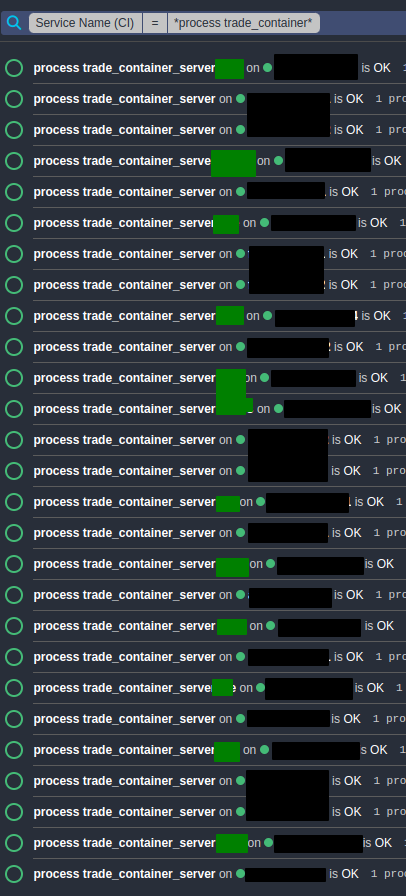
I have 27 services called process trade_container_server*:
but ScheduledDowntime Apply Rule is assigned only to 14 of them:
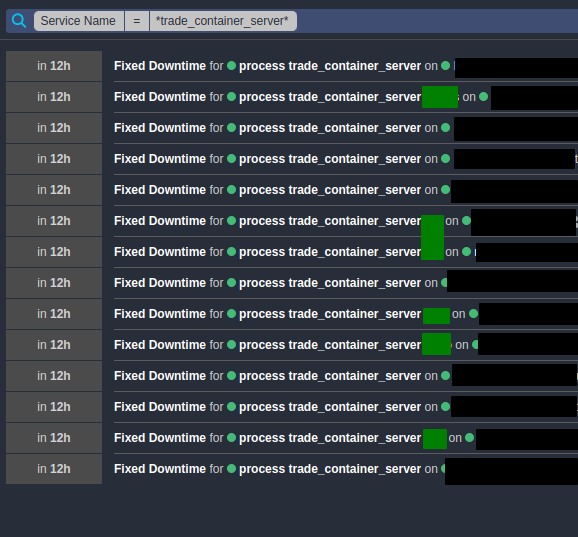
As you can see, some of these services have names like process trade_container_server, some of them are called process trade_container_server xyz.
Assignment of Scheduled Downtime seems to be pretty random. All these services have been deployed before ScheduledDowntime Apply Rule has been created.
Does anyone have an idea why it is not assigned to all of these services that are even sharing the same name sometimes (but different host)?
This is the configuration we are using:
- Director version: 1.10.2
- Icinga Web 2 version: 2.11.4
- modules: director, grafana, icingadb, incubator
- Icinga 2 version: r2.13.7-1
- Operating System and version: Debian 11