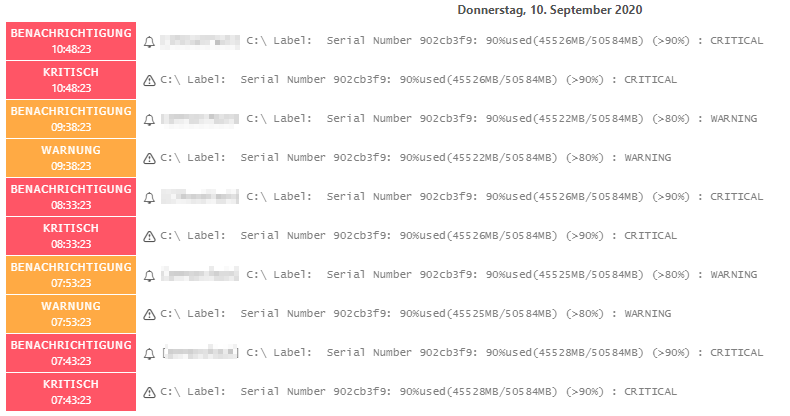
just stumbled upon a “bunch of problems” in a customers system.
The system is “constantly” sending messages for checks that have already sent a notification.
And it looks like the checks that are in a non-ok state are behaving like volatile checks:
As you can see the switch from critical to unknown directly becomes a hard state as well as vice versa AND it’s triggering a re-renotification.
Is this normal behavior?
volatile was set to false in the service template.
I just changed the notification rules to be separate for the 24/7 and non-workhours users, to be able to delay notifications for the latter.
Maybe this will also fix this strange behavior, will check in the next couple of days.
Any other ideas were to look are apprechiated
Cheers
Will update from 2.11.3 to 2.12 today, but I don’t expect it to change anything
UPDATE:
Did the icinga update to v2.12 (at around 9.30), but it didn’t help.
Also did a rm -fr /var/lib/icinga2/api/ to “kind of reset” the notifications.
So the notification at 09:51 was not a surprise, but then the same behavior goes on.
Debug Log from 10:27
[2020-09-16 10:27:25 +0200] notice/Process: PID 10336 ('/usr/lib/nagios/plugins/check_snmp_storage.pl' '-C' 'public' '-H' 'ip' '-c' '90' '-f' '-m' 'C:' '-t' '50' '-w' '80') terminated with exit code 2
[2020-09-16 10:27:25 +0200] debug/Checkable: Update checkable 'HOSTNAME!disk-c' with check interval '300' from last check time at 2020-09-16 10:27:25 +0200 (1.60024e+09) to next check time at 2020-09-16 10:32:19 +0200 (1.60025e+09).
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::SetNextCheck' message
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::CheckResult' message
[2020-09-16 10:27:25 +0200] notice/Checkable: State Change: Checkable 'HOSTNAME!disk-c' hard state change from UNKNOWN to CRITICAL detected.
[2020-09-16 10:27:25 +0200] information/Checkable: Checkable 'HOSTNAME!disk-c' has 2 notification(s). Checking filters for type 'Problem', sends will be logged.
[2020-09-16 10:27:25 +0200] notice/Notification: Attempting to send notifications of type 'Problem' for notification object 'HOSTNAME!disk-c!alle-Servicechecks_User2'.
[2020-09-16 10:27:25 +0200] notice/Notification: Not sending notifications for notification object 'HOSTNAME!disk-c!alle-Servicechecks_User2': before specified begin time (15 minutes)
[2020-09-16 10:27:25 +0200] notice/Notification: Attempting to send notifications of type 'Problem' for notification object 'HOSTNAME!disk-c!alle-Servicechecks_User1'.
[2020-09-16 10:27:25 +0200] debug/Notification: Type 'Problem', TypeFilter: Custom, Problem and Recovery (FType=32, TypeFilter=104)
[2020-09-16 10:27:25 +0200] debug/Notification: State 'Critical', StateFilter: Critical, OK and Warning (FState=4, StateFilter=7)
[2020-09-16 10:27:25 +0200] debug/Notification: User 'ITPostfach' notification 'HOSTNAME!disk-c!alle-Servicechecks_User1', Type 'Problem', TypeFilter: Problem (FType=32, TypeFilter=104)
[2020-09-16 10:27:25 +0200] debug/Notification: User 'ITPostfach' notification 'HOSTNAME!disk-c!alle-Servicechecks_User1', State 'Critical', StateFilter: Critical, Down and Warning (FState=4, StateFilter=38)
[2020-09-16 10:27:25 +0200] information/Notification: Sending 'Problem' notification 'HOSTNAME!disk-c!alle-Servicechecks_User1' for user 'ITPostfach'
[2020-09-16 10:27:25 +0200] notice/Process: Running command '/etc/icinga2/scripts/mail-service-notification.sh' '-4' 'ip' '-6' '' '-b' '' '-c' '' '-d' '2020-09-16 10:27:25 +0200' '-e' 'disk-c' '-l' 'HOSTNAME' '-n' 'HOSTNAME' '-o' 'C:\ Label: Serial Number a405ab64: 91%used(74301MB/81417MB) (>90%) : CRITICAL ' '-r' 'MAILADDRESS' '-s' 'CRITICAL' '-t' 'PROBLEM' '-u' 'disk-c': PID 10339
[2020-09-16 10:27:25 +0200] information/Notification: Completed sending 'Problem' notification 'HOSTNAME!disk-c!alle-Servicechecks_User1' for checkable 'HOSTNAME!disk-c' and user 'ITPostfach' using command 'mail-service-notification'.
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::SendNotifications' message
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::SetForceNextNotification' message
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::NotificationSentToAllUsers' message
[2020-09-16 10:27:25 +0200] notice/ApiListener: Relaying 'event::NotificationSentUser' message
[2020-09-16 10:27:25 +0200] notice/Process: PID 10339 ('/etc/icinga2/scripts/mail-service-notification.sh' '-4' 'ip' '-6' '' '-b' '' '-c' '' '-d' '2020-09-16 10:27:25 +0200' '-e' 'disk-c' '-l' 'HOSTNAME' '-n' 'HOSTNAME' '-o' 'C:\ Label: Serial Number a405ab64: 91%used(74301MB/81417MB) (>90%) : CRITICAL ' '-r' 'MAILADDRESS' '-s' 'CRITICAL' '-t' 'PROBLEM' '-u' 'disk-c') terminated with exit code 0
I’m still not sure if this is a correct behavior.
From my point of view there should be no re-notification after a change fromcrit->unknown->critas there is noOKstate inbetween, which would resetno_more_notifications to false.