Hi Team,
I have installed master zone with 2 nodes: master01, master02.
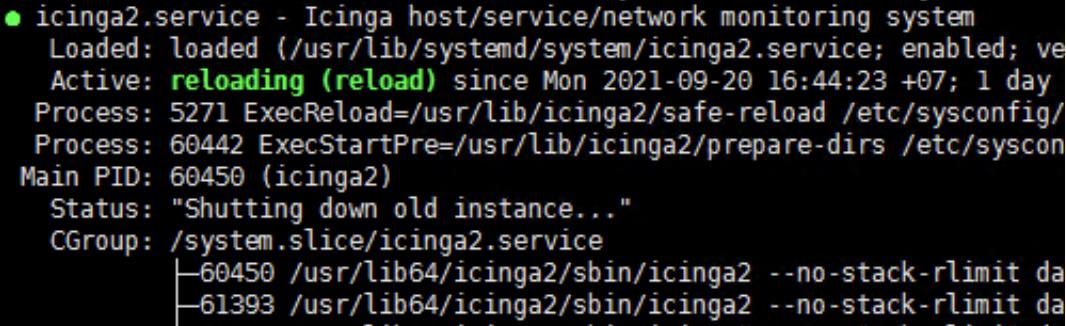
I frequently (about once a week) get “backend icinga not running” error after deploy configuration from Icinga Director.
When this error is encountered, the icinga2 service on the active endpoint(master02) is reloading. I have to manualy restart service to work properly.
I tried turning off master02 to debug, but this still occurs with master01.
I have consulted similar topics about “Backend icinga not running” but there is no solution for this case.
Can someone help me, please!
Enviroment
Version used (icinga2 --version): v2.13.1-1
Operating System and version: CentOS 7
Enabled features (icinga2 feature list): api checker ido-mysql influxdb mainlog notification
Icinga Web 2 version and modules (System - About): icingaweb2 v2.8.2, module: director, fileshipper, grafana, incubator, ipl, monitoring, reactbundle
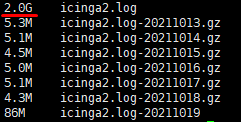
I will increase the log level to notice for more information. Does the file size increase quickly?
The error happens randomly so I can’t enable debug log. (It’s too large)
Thanks!
“Quickly” is going to depend on your restraints, and how many events are generated (usually depending on how large your environment is). You could and should setup your logs to rotate – start with daily if you think it’s going to be big, and then you can work your way down from there if needed.
Hi guys, we were running into this issue also not long ago. We found that there were some issues with the configuration so it was not able to sync correctly. To start try look at the configuration with icinga daemon -c. We ended up clearing the staging directory and everything went back to normal. In our case one of the problems was a user group not set in a global zone.