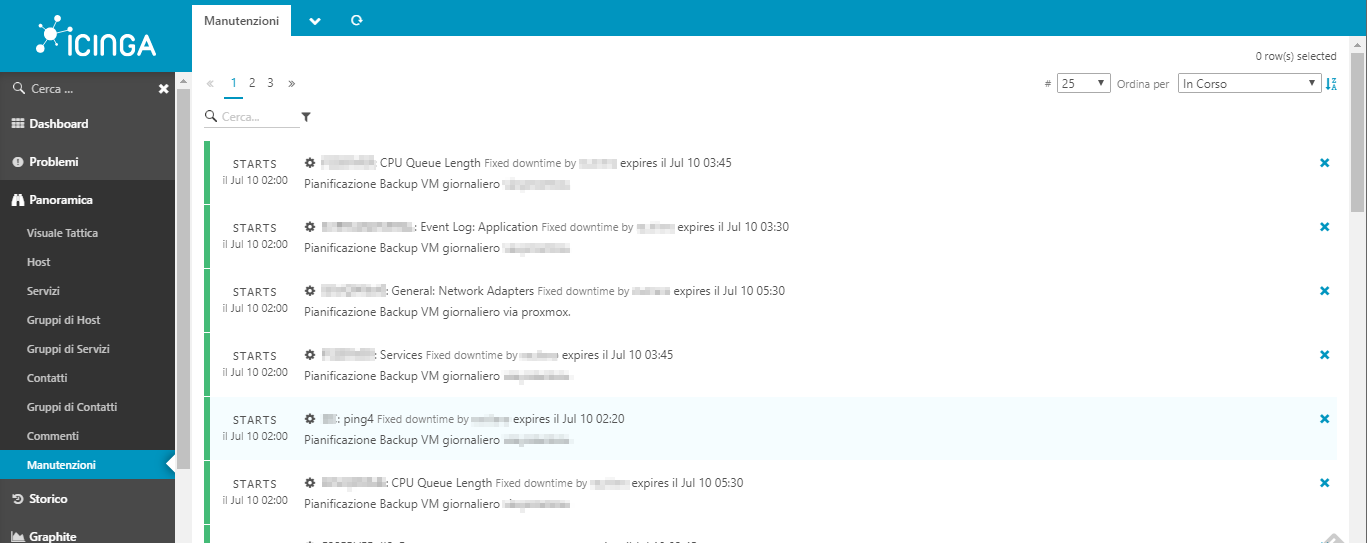
Hi,
I have configured the downtimes.conf file including all the hosts that must be excluded from the control during the backup phases, and it works correctly for most of the hosts except for three of them for which I continue to receive “Host xxxx is DOWN”, for the duration of the backup.
I don’t think this is the problem, because even for all the other hosts (except three) I don’t have scheduled downtime but it works correctly in fact notifications don’t arrive during the pre-established downtime.
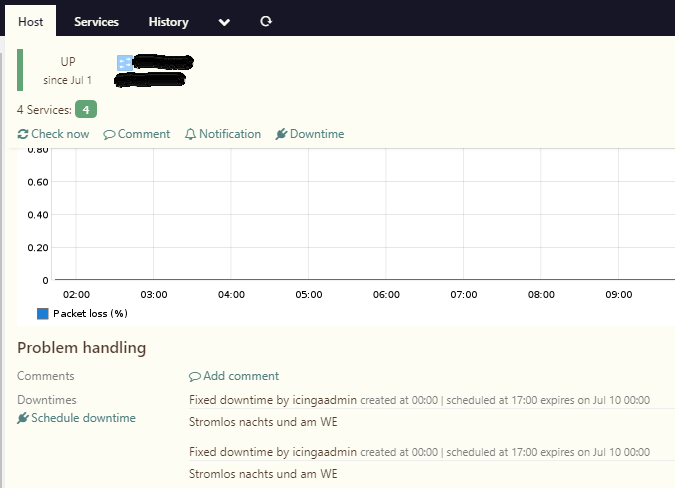
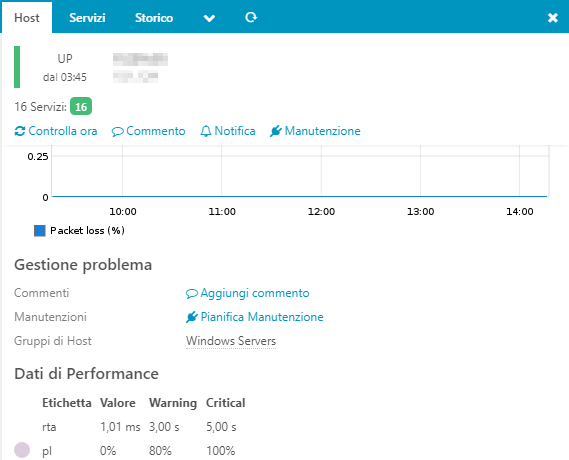
A ScheduledDowntime config object generates Downtime objects on demand at runtime, one for the next slot and once expired, the next and so on. The downtimes you’ll see in Icinga Web 2, are runtime downtimes - not comparable to ScheduledDowntime objects.
If it is easier to divide, mark a ScheduledDowntime as “recurring downtime” in your brain, while a “downtime” is just a runtime object.
In fact inside the folder /var/lib/icinga2/api/packages/_api/04b4c295-4f89-4f17-9ee3-3b0305be65ce/conf.d/downtimes I compared the two types of downtime relating to a service, the first created with the runtime and the second via icingaweb and the result is the following.
authoritative_zone is a special attribute for ScheduledDowntime generated objects, there’s no specific difference here.
In order to troubleshoot further, I’d suggest modifying the notification apply rule, command and script and add a parameter for passing the value of $host.downtime_depth$. If this is 0, you’ll know that the downtime wasn’t triggered (or none existed).
To dig deeper, I’d modify the notification script and query the REST API with some curl commands, e.g. the runtime state of /v1/objects/downtimes filtered by the host.name. In the event of the notification, this adds more details - do that for a host where only you get notified from though.